If you missed the tweet… 2+ years ago I predicted here that Teradata would go away from ByNet… and lo and behold they did (see here).
In the same post I predicted that Netezza would go away from FPGAs. This has not come to pass. But I wonder if it might… or if there is a bigger change possible?
With the recent announcements of DB2 BLU and column store I suspect that DB2 will outperform Netezza when the query mix does not fall directly in Netezza’s sweet spot.
I also have a suspicion that the Netezza architecture, with its execution engine split across two different processors, is just hard to engineer. I cannot think of another reason features come so slowly there. Why, for example, is there no columnar support? Greenplum built it on the same Postgres base with less than a handful of engineers in a year. Teradata now offers columnar tables as well.
These concerns… combined with some previous notes on Netezza add up as follows:
FPGAs no longer provide a performance advantage (per my link above)
FPGAs limit the ability of the DBMS to use more cores (see here)
FPGAs limit the ability of the DBMS to manage workload (see here… and especially the comments)
FPGAs and having a 2-phase split execution environment limits the ability to extend and enhance the code base (a new conjecture)
Zone Maps and CBTs provide a limited ability to solve for a wide range of queries… they are just an index (see here)
DB2 Column Store provides a performance boost equal to or greater than zone maps and CBTs (a new conjecture)
DB2 BLU provides a performance boost well in excess of what Netezza can provide (see here)
The Netezza architecture with FPGAs provided a distinct advantage in 2000 when CPU was the scarce commodity. But multi-core systems and the advance of Moore’s Law soon made processing abundant… and the advantage of FPGA co-processing diminished. Without a distinct advantage the split execution architecture became a disadvantage… and the complexity of that design kept Netezza from developing the advances on top of the Postgres base that were very easy to develop by others.
Architecture counts… and DB2 is a strong product. If, as I suspect, DB2 is now a more capable product than Netezza… I wonder what path IBM may take?
If Greenplum HAWQ does not look promising (see my previous posts on HAWQ here and here) what are the prospects for TeradataAster Data… which aspires to both replace and/or co-exist with Hadoop for a fee? Teradata+Hadoop maybe… but Teradata+Aster+Hadoop seems like one layer too many… as does Aster+Hadoop.
(OK, I removed the bad “HAWQing” pun in the title… no complaints from readers… it just seemed unfair… – Rob)
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
From a technical perspective, Greenplum is my favorite data warehouse database. Built on the same architecture as Teradata (see here), the Greenplum team was able to extend the core of Postgres… first building out a shared-nothing architecture and then adding feature after feature… putting the heat on the other major players. Greenplum was the first row-based RDBMS to add full columnar support… and their data-loading capability is second-to-none.
Oddly they do not want to be in the data warehouse space. Their recent announcement (here) does not include any reference to data warehousing or business intelligence. The tweets from @Greenplum, the Greenplum website, and all things marketing are focussed on analytics and/or Hadoop. Even their page on data warehousing (here) has no articles on data warehousing. It is just not their target market. That is fine… the product is still a great EDW platform… but it is a worry.
Where They Win
The reason they target analytics is because they excel there. If your warehouse workload clogs because of big, complex, queries… Greenplum can win the day. Their data flow architecture, which keeps tuples moving from execution step to execution step without writing to spool provides them with the ability to beat the competition on analytics. They provide a very rich set of in-database analytics and some add-on capabilities to improve the productivity of your data scientist team.
Their data load architecture, which they call scatter-gather, is a big differentiator. If your problem is that you cannot get data loaded and reports out in your nightly batch window then the combination of scatter-gather and the ability to run big report queries is unbeatable.
Greenplum also has a unique solution for near-real-time. They marry Gemfire, an in-memory object-oriented database, with scatter-gather to move small batches of inserted data to Greenplum with a very small time delta. I do not believe this solution supports inserts or deletes as they have to be applied directly to the Greenplum database… but it is a nice capability for a certain class of problems.
Where They Lose
Greenplum, like Teradata, can be beat when the problem to be solved is narrow. In these cases, when the database supports a single application with a small number of queries or when it supports a narrowly focussed data mart, they are vulnerable to Netezza, Vertica, or even Exadata. It is also sometimes the case that a poorly designed POC can narrow the scope enough that Greenplum loses.
Greenplum can also lose when a full EDW is required. The basic architecture of the RDBMS is capable of supporting an EDW… but some of the operational features required… RASR, workload, incremental backup, etc. are not mature. This may well be the intentional result of their focus away from these features at analytics.
In the Market
Despite the worries Greenplum should be included in every POC. They will push Teradata hard in performance and in price/performance.
As noted here… I do not understand their market strategy. It seems that they are competing with themselves by offering Hadoop for analytics… but this cannot be a bad thing for customers even if it is an odd position in the market. The analytics market they favor is tough… relatively small (compared to the DW space)… emerging… there are several capable competitors… and the market is haunted by the same problem that killed the data mining market in the mid-1990’s… there are just not enough skilled data scientists (see here).
My Guess at the Future
I cannot guess at the future of Greenplum… They are being moved into a new business unit that could be spun into a new company that has a charter to build software for the cloud (see here). This is odd in several dimensions. First, as I noted here, the shared nothing architecture Greenplum is built on is not a perfect fit for the cloud. There are ways to get around this (maybe the topic for a future post?) but it will require development in a fundamentally new direction. Further, the new division seems to be a software-only venture. This makes the future of the EMC Greenplum Data Computing Appliance uncertain. I suppose that there will be announcements soon to clarify these questions… but the architectural disconnects make it likely that there will be some arm-waving for a while.
The TwinFin Surf Board (Photo credit: tvanhoosear)
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
Netezza put a new spin on data warehousing… they made it easy. The Netezza software includes a unique clustered index feature called a zone map that is powerful and easy to use. They also use a FPGA co-processor to augment the CPUs, offloading data compression and projection. When both of these innovations combine Netezza is hard to beat.
Zone maps are powerful when they can be used in a query plan… but the hardware is only good, not great, when zone maps are not in the plan. FPGAs provided a huge boost when Netezza first came on the scene… but as discussed here they do not provide the same boost today. In addition, FPGAs may limit the ability of a Netezza cluster to handle concurrent queries (see here and especially the comments).
The IBM acquisition has opened up a market of Blue shops to Netezza… so they are selling… and as a result Netezza is here to stay.
Where They Win
Of course, Netezza will win in all-Blue shops.
Netezza wins when there is a naturally sequenced field in each big table that is also used in the predicate for most queries. For example, if data is naturally in date/time sequence and every query has a date/time constraint then Netezza is hard to beat. This is the case most often for focussed data marts or single application databases… so look for Netezza for these sort of problems.
Netezza wins when there are a relatively small number of concurrent queries… and they can win when the queries are complex… as long as the zone map is in the plan.
Netezza can win when the POC is designed such that zone maps may be used in the POC… for example when the POC models only a single data load and the data is pre-sorted… even when the real application would fragment the data (for example… data will not naturally enter the warehouse sequentially by customer number… the same customer will be represented time and again… but if you load once only for a POC then you can sort by customer number and use it in the query predicates).
Note that I am not saying that Netezza is a poor performer when zone maps are not used… it is good… but they would never win a POC if no queries used the zone map.
Where They Lose
Guess what? Netezza loses when the zone maps cannot be used or can be used for only a small fraction of the query workload. Note again that the use of a zone map depends on two factors: the data has to be in sequence over all time, and the queries must use the columns mapped in the predicate. If data enters the system out of sequence then the zone map fragments and eventually loses the ability to speed up queries (a few random out of sequence rows are OK).
This constraint makes it hard for Netezza to service data warehouses where, by definition, lots of different user constituencies come at the data from lots of different directions… rather than always using the path grooved with a zone map.
Netezza was designed when only Sybase IQ had columnar oriented tables… today columnar is in nearly every DW database and this allowed the competition to cut deeply into Netezza’s competitive, zone-map enabled, edge. Teradata columns, Greenplum columns, or the natural column stores can win even when zone maps are on target.
Bottom line: do a POC…
In the Market
I spend most of my time in the general market for data warehousing. You won’t see me offer much of an opinion on HANA for BW, for example… even though there are ten thousand plus BW warehouses I just do not see them in the places I work.
Before Netezza was acquired by IBM they were everywhere… in nearly every POC. Now… not so much. To a very large extent they seem to have been directed into the Blue-only customer base (now that I think about it the same thing happened to the Ascential Data Stage suite of ETL products).
My Guess at the Future
As I noted in the reference above… I think that Netezza will eventually go away from the co-processor strategy.
There have been rumors for several years of design that allowed multiple zone maps. This would be very important… but loading out-of-sequence data, which is the necessary the result, could be very slow.
Netezza has lost some of its edge as other technologies added columnar capabilities to their technologies… and Netezza is surely looking at this… but their architecture which includes an execution engine on the server and on the FPGA makes this more complex than you might suspect. Zone maps and two-stage optimization (one in the server and once in the FPGA) is cool… but a tight coupling of the tricks makes for a difficult time extending and adding new features.
If I were the King of Netezza and I could not find a reasonable way to extend beyond the two tricks that got me here I would go with the flow… I would position Netezza as an extremely easy-to-deploy data mart appliance and hook it tightly (i.e. build in some integration) along-side DB2 and Hadoop… and I would cede the EDW space to DB2 and the Big Data space to Hadoop.
Next up… my 2 Cents on Greenplum
May 1, 2013: Here is an update, or maybe a summary, of my view on Netezza… – Rob
If I were the Register I would have titled this: Raging Stuffed Elephant To Devour Two Warehouse Vendors… I love the Register… if you do not read it have a look…
This is a post is about the market implications of architecture…
Let us assume that Hadoop matures and finds a permanent place in the market. This is not certain with some folks expressing concern (here) and others boundless enthusiasm (here). So let’s assume… and consider where it might fit.
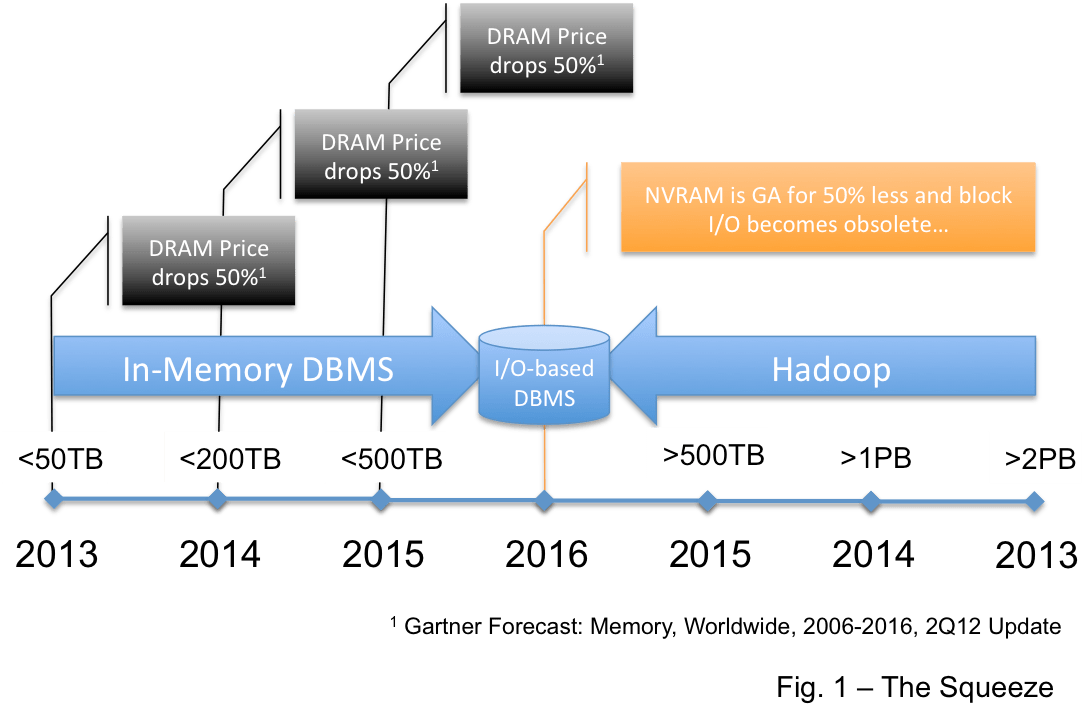
One place is in the data warehouse market… This view says Hadoop replaces the DBMS for data warehouses. But the very mature BI/DW market requires a high level of operational integrity and Hadoop is not there yet… it is advancing rapidly as an enterprise platform and I believe it will get there… but it will be 3-4 years. This is the thinking I provided here that leads me to draw the picture in Figure 1.
It is not that I believe that Hadoop will consume the data warehouse market but I believe that very large EDW’s… those over 1PB… and maybe over 500TB will be compelled by the economics of “free” to move big warehouses to Hadoop. So Hadoop will likely move down into the EDW space from the top.
Another option suggests that Big Data will be a platform unto itself. In this view Hadoop will sit beside the existing BI/DW platform and feed that platform the results of queries that derive structure from unstructured data… and/or that aggregate Big Data into consumable chunks. This is where Hadoop sits today.
In data warehouse terms this positions Hadoop as a very large independent analytic data mart. Figure 2 depicts this. Note that an analytics data mart, and a Hadoop cluster, require far less in the way of operational infrastructure… they share very similar technical requirements.
This leads me to the point of this post… if Hadoop becomes a very large analytic data mart then where will Greenplum and Netezza fit in 2-3 years? Both vendors are positioning themselves in the analytic space… Greenplum almost exclusively so. Both vendors offer integrated Hadoop products… Greenplum offers the Greenplum database and Hadoop in the same hardware cluster (see here for their latest announcement)… Netezza provides a Hadoop connector (here). But if you believe in Hadoop… as both vendors ardently do… where do their databases fit in the analytics space once Hadoop matures and fully supports SQL? In the next 3-4 years what will these RDBMSs offer in the big data analytics space that will be compelling enough to make the configuration in Figure 3 attractive?
I know that today Hadoop cannot do all that either Netezza or Greenplum can do. I understand that Netezza has two positions in the market… as an analytic appliance and as a data mart appliance… so it may survive in the mart space. But the overlap of technical requirements between Hadoop and an analytic data mart… combined with the enormous human investment in Hadoop R&D, both in the core and in the eco-system… make me wonder about where “Big Data” analytic relational databases will fit?
Note that this is not a criticism of the Greenplum RDBMS. Greenplum is a very fine product, one of the best EDW platforms around. I’ll have more to say about it when I provide my 2 Cents… But if Figure 2 describes the end state for analytics in 2-3 years then where is the place for the Figure 3 architecture? If Figure 3 is the end state then I do not see where the line will be drawn between the analytic workload that requires Greenplum and that that will run on Hadoop? I barely can see it now… and I cannot see it at all in the near future.
Both EMC Greenplum and IBM seem to strongly believe in Hadoop… they must see the overlap in functionality and feel the market momentum of Hadoop. They must see, better than most, that Hadoop wins this battle.
Here is a true story… fuzzed just a little to disguise the real-life characters…
Three years ago… a friend calls to say: “Our new CxO just informed us that we needed to install a 1000-node Hadoop cluster in the next two months. I said… cool, what is the use case? He says… don’t argue with me… just get 1000 nodes up and running in the next 60 days. I say: there is no floorspace or power for that large a system. He says: do it in the next 60 days!”
My friend then decommissioned several systems that were doing productive, but expendable work, and installed 1000 nodes of Hadoop. And it sat there with no business problem to solve.
Today there is a little work running on the cluster… adding far less value than the expendable work that was decommissioned. The CxO is gone… with a glowing resume that says that he deployed one of the World’s largest Hadoop clusters.
When the hype over a technology gets so amplified that the hypers start hyping about the level of the hype… Hype-squared… you know that disillusionment cannot be far behind. Gartner is pretty spot on with their Hype Cycle (see here)… but Hadoop may survive, methinks.
Readers… any other good Hadoop hype stories to share?
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
To help pay the bills please consider this as you read on…
Summary
OK, I hate Oracle marketing (see here and here). They are happy to skirt the edge of the credible too often. But let’s be real… Exadata was a very smart move… even if it a flawed product. The flaws are painful but not fatal… and Oracle can now play in the data warehouse space in places they could not play before. I do not believe that Exadata is a strong competitor as you will see below… it will not win many “fair” POCs… but the fight will be more than close enough to make customers with existing Oracle warehouses pick Exadata once they consider the cost of migration. This is tough… it means that customers are locked in to a relatively weak alternative… and every Oracle customer (and every Teradata customer and every SQL Server customer and every DB2 customer) should consider the long-term costs of vendor lock-in. But each customer has to weigh this for themselves… and this evaluation of the cost of lock-in is about neither architecture nor marketing…
Where They Win
First and foremost Exadata wins when there is an existing data warehouse or data mart on Oracle that will have to be migrated. My recommendation to customers is that they think about this carefully before they engage other vendors. It is a waste of everybody’s time to consider alternatives when in the end no alternative has a chance… and it is a double waste to do a POC when even a big technical win by a competitor cannot win them the business.
Exadata can win technically when the data “working set” is small. This allows Exadata to keep the hot data in SSD and in memory and better still, in the RAC layer. This allows Oracle to win POCs where that can suggest a subset of the EDW data is all that is required.
Exadata can win when the queries required, or tested, contain highly selective predicates that can be pushed down in the first steps of the explain plan. Conversely, Exadata bonks when lots of data must be pulled to the RAC layer to perform a join step.
Where They Lose
Everyone who has an Exadata system or who is considering one should view the two videos here. The architectural issues are apparent… and you can then consider the impact for your workload.
As noted above… in an Exadata execution plan the early simple table scans and projection are executed in the storage layer… subsequent steps occur in the RAC layer… if lots of data has to be moved up then the cluster chokes.
There are times when the architectural limitations are just too large and a migration is required to meet the response time requirements for the business. This often happens when Exadata is to support a single application rather than a data warehouse workload… In other words, if the cost of migrating away from Oracle is small, either because the applications to be moved are small or because an automated tool is available to mitigate the cosy or because the migration costs are subsidized by another source, then Exadata can lose even when there is a migration required.
Exadata can be beat on price… unless you count the cost of migration.
In the Market
For the reasons above, Exadata wins for current Oracle customers. There was a honeymoon when Exadata was winning some greenfield deals against other competitors… but these are now more rare.
My Guess at the Future
I think that the basic architecture of Exadata is defensible… having a split configuration is , after all, not completely foreign. Teradata and Greenplum and others use master nodes split from data nodes… and this is where is I predict we’ll see Oracle go. Over time, more execution steps will move to the storage layer and out of the RAC layer and in the end, Exadata will look ever more like a shared-nothing implementation. This just has to be the architectural way forward for Exadata (but don’t expect LE to stand up anytime soon and admit that he was wrong all of these years about the value of a shared-nothing architecture).
Phil has alerted us that there will be some OLTP/BI enhancements coming (see the comments section here)… which stole away a prediction I would have made otherwise.
The bottlenecks pointed out by Kevin Closson (as above and more here) need to be addressed… but to some extent these issues are the result of hardware constraints… and the combination of better hardware configurations and the push-down of more execution steps can mitigate many of the issues.
It will be a while before the Exadata architecture evolves to a point where the product is more competitive… and from now to then I think the World will be as I described it above… Oracle zealots will pick Exadata either as a religious stance or to avoid the cost of a migration… others will mostly go elsewhere…
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
Teradata Storage Rack (Photo credit: pchow98)
Summary
Despite my criticisms of some of their market positions (here, here, here, and here) Teradata provides the single best data warehouse platform in the market, hands-down. As an EDW, or data mart it is the best. It will be very competitive as an analytics mart and/or as an operational data store. It has a very complete eco-system of utilities and offers a robust set of Reliability, Availability, Serviceability, and Recoverability (RASR) features to make the eco-system solid. Performance is very good… Teradata should win more POCs than they lose… and they have become more competitive on price… so their price/performance is good if not great.
I recommend a POC for most customers in most cases… you can often save 20%-30% in a competitive situation.. but if you don’t have any special requirements… if you are building a standard BI/DW eco-system then Teradata would be the only vendor I would trust without a POC.
Where They Win
Now that they support columnar tables and columnar projection Teradata should win way more POCs than they lose (before columnar support they could lose to the column stores or to hybrids like Greenplum). The Teradata optimizer is very robust. It efficiently solves for a broad array of queries, and for a mixed workload that cuts across the data is many ways. This makes Teradata well-suited as the platform for an EDW.
Every RDBMS has a sweet spot where they win… so Teradata will not win every POC. But if you POC for an EDW and you prove with a full contingent of data, with queries that cut across the data in several ways, with a fair emulation of data loading, querying, loading , and querying… with a full workload… Teradata is tough to beat.
Where They Lose
The shared-nothing architecture is an imperfect fit on a single node… so other players can win smaller data warehouses that can fit on 1-2 nodes. In addition, they can be beat for very large configurations (1PB and above…) by Hadoop.
Teradata can be beat when the workload consists of very complex queries and/or where the problem to be solved requires fantastic response on a small number of CPU-intensive queries… this is a side-effect of spooling the intermediate results to a block device.
Teradata can be beat when data is trickled in at a high, continuous, rate.
Teradata can be beat when a query set goes through the data in a narrow way, using a single index or the equivalent, as might be the case for a data mart.
Teradata can be beat on price.
In the Market
For the reasons above, Teradata is the leader in the DW platform market. Recent competition from Exadata, Netezza, Greenplum, Vertica… and now HANA… has cut margins but not impacted business growth too much. Competitors have projected Teradata’s demise for 20 years now… but the product continues to set the standard.
As noted here, I believe that Hadoop will squeeze Teradata at the 1PB level and above…
My Guess at the Future
Teradata has three architectural challenges to address… and I suspect they will manage all three more-or-less.
First, the old architecture which was designed for very small DRAM configurations forces unnecessary I/O in violation of Gray and Putzolu’s Five Minute Rule (see here). This will be mitigated in the short-term by writing spool to SSD devices… and in the medium term by writing spool to NVRAM. If these mitigations are not sufficient then Teradata may have to consider re-engineering in a data flow scheme… but this will be tough.
Next, there are several advances in network technology coming in the next 2-3 years… and software defined networks will impact the space as well. ByNet may have served its purpose… providing Teradata with a significant edge for 20+ years… but Teradata may consider moving to an off-the-shelf network (see here).
Finally, a truly active data warehouse requires support for simultaneous OLTP and BI workloads… I would expect Teradata to build in the sort of hybrid OLTP/BI table capability now supported by both Vertica and HANA… and quasi-supported by Gemfire/Greenplum.
Teradata has some interesting business challenges as their margins shrink… and one of those challenges is that their expensive 3-person relationship/technical/industry sales team approach will face some pressure. But it is these sales teams that also provide Teradata an edge. They are the only databases vendor who can field team after team of veterans who understand both the technology and the vertical space.
If I were King of Teradata I might try to push downstream and build a configuration optimized for the low end. This would not be a high-margin hardware business but it would sell services and increase market share.
I posted a blog on the SAP site here that discussed the implications of mobile clients. I want to re-emphasize the issue as it is crucial.
While at Greenplum we routinely replaced older EDW platforms and provided stunning performance. I recall one customer in particular where we were given a query that ran in 7 hours and Greenplum executed the query in seven seconds. This was exceptional… more typical were cases where we reduced run-times from several hours to under 30 minutes… to 10 minutes… to 5 minutes. I’m sure that every major competitor: Teradata, Greenplum, Netezza, and Exadata has similar stories to tell.
But 5 minutes will not cut it if you are servicing a mobile client where sub-second response to the device is a requirement… and 10 minutes is out of the question. It does not matter if it ran in 10 hours before… 10 minute response is not acceptable to a mobile device.
Today we see sub-second response delivered to our phones by custom applications built on special high-performance platforms designed specifically to service a mobile client: iPhones, iPads, and Android devices.
But what will we do about the BI applications built on commercial platforms which have just used every trick in the book to become one of the 5 minute stories mentioned above?
I think that there are only a couple of architectural choices.
We can rewrite the high-value queries as custom applications using specialized infrastructure… at great expense… and leaving the vast majority of queries un-serviced.
We can apply the 80/20 rule to get the easiest queries serviced with only 20% of the effort. But according to Murphy the 20% left will be the highest value queries.
We can tack on expensive, specialized, accelerators to some queries… to those that can be accelerated… but again we leave too much behind.
Or we can move to a general purpose high performance computing platform that can service the existing BI workload with sub-second response.
In-memory computing will play a role… Exalytics provides option #3… HANA option #4.
SSD devices may play a role… but the performance improvements being quoted by vendors who use SSD as a block I/O device is 10X or less. A 10X improvement applied to a query that was just improved to 10 minutes yields a 1 minute query… still not the expected level of service.
IT departments will have to evaluate the price/performance, not just the price, as they consider their next platform purchases. The definition of adequate response is changing… and the old adequate, at the least cost, may not cut it. Mobile clients are here to stay. The productivity gains expected from these devices is significant. High performance BI computing is going to be a requirement.
When I was at Greenplum… and now again at SAP… I ran into a strange logic from Teradata about query concurrency. They claimed that query concurrency was a good thing and an indicator of excellent workload management. Let’s look at a simple picture of how that works.
In Figure 1 we depict a single query on a Teradata cluster. Since each node is working in parallel the picture is representative no matter how many nodes are attached. In the picture each line represents the time it takes to read a block from disk. To make the picture simple we will show I/O taking only 1/10th of the clock time… in the real world it is slower.
Given this simplification we can see that a single query can only consume 10% of the CPU… and the rest of the time the CPU is idle… waiting for work. We also represented some I/O to spool files… as Teradata writes all intermediate results to disk and then reads them in the next step. But this picture is a little unfair to Greenplum and HANA as I do not represent spool I/O completely. For each qualifying row the data is read from the table on disk, written to spool, and then read from spool in the subsequent step. But this note is about concurrency… so I simplified the picture.
Figure 2 shows the same query running on Greenplum. Note that Greenplum uses a data flow architecture that pushes tuples from step to step in the execution plan without writing them to disk. As a result the query completes very quickly after the last tuple is scanned from the table.
Let me say again… this story is about CPU utilization, concurrency, and workload management… I’m not trying to say that there are not optimizations that might make Teradata outperform Greenplum… or optimizations that might make Greenplum even faster still… I just want you to see the impact on concurrency of the spool architecture versus the data flow architecture.
Note that on Greenplum the processors are 20% busy in the interval that the query runs. For complex queries with lots of steps the data flow architecture provides an even more significant advantage to Greenplum. If there are 20 steps in the execution plan then Teradata will do spool I/O, first writing then reading the intermediate results while Greenplum manages all of the results in-memory after the initial reads.
In Figure 3 we see the impact of having the data in-memory as with HANA or TimeTen. Again, I am ignoring the implications of HANA’s columnar orientation and so forth… but you can clearly see the implications by removing block I/O.
Now let’s look at the same pictures with 2 concurrent queries. Let’s assume no workload management… just first in, first out.
In Figure 4 we see Teradata with two concurrent queries. Teradata has both queries executing at the same time. The second query is using up the wasted space made available while the CPUs wait for Query 1’s I/O to complete. Teradata spools the intermediate results to disk; which reduces the impact on memory while they wait. This is very wasteful as described here and here (in short, the Five Minute Rule suggests that data that will be reused right away is more economically stored in memory)… but Teradata carries a legacy from the days when memory was dear.
But to be sure… Teradata has two queries running concurrently. And the CPU is now 20% busy.
Figure 5 shows the two-query picture for Greenplum. Like Teradata, they use the gaps to do work and get both queries running concurrently. Greenplum uses the CPU much more efficiently and does not write and read to spool in between every step.
In Figure 6 we see HANA with two queries. Since one query consumed all of the CPU the second query waits… then blasts through. There is no concurrency… but the work is completed in a fraction of the time required by Teradata.
If we continue to add queries using these simple models we would get to the point where there is no CPU available on any architecture. At this point workload management comes into play. If there is no CPU then all that can be done is to either manage queries in a queue… letting them wait for resources to start… or start them and let them wastefully thrash in and out… there is really no other architectural option.
So using this very simple depiction eventually all three systems find themselves in the same spot… no CPU to spare. But there is much more to the topic and I’ve hinted about these in previous posts.
Starting more queries than you can service is wasteful. Queries have to swap in and out of memory and/or in and out of spool (more I/O!) and/or in and out of the processor caches. It is best to control concurrency… not embrace it.
Running virtual instances of the database instead of lightweight threads adds significant communications overhead. Instances often become unbalanced as the data returned makes the shards uneven. Since queries end when the slowest instance finishes it’s work this can reduce query performance. Each time you preempt a running query you have to restore state and repopulate the processor’s cache… which slows the query by 12X-20X. … Columnar storage helps… but if the data is decompressed too soon then the help is sub-optimal… and so on… all of the tricks used by databases and described in these blogs count.
But what does not count is query concurrency. When Teradata plays this card against Greenplum or HANA they are not talking architecture… it is silliness. Query throughput is what matters. Anyone would take a system that processes 100,000 queries per hour over a system that processes 50,000 queries per hour but lets them all run concurrently.
I’ve been picking on Teradata lately as they have been marketing hard… a little too hard. Teradata is a fine system and they should be proud of their architecture and their place in the market. I am proud to have worked for them. I’ll lay off for a while.