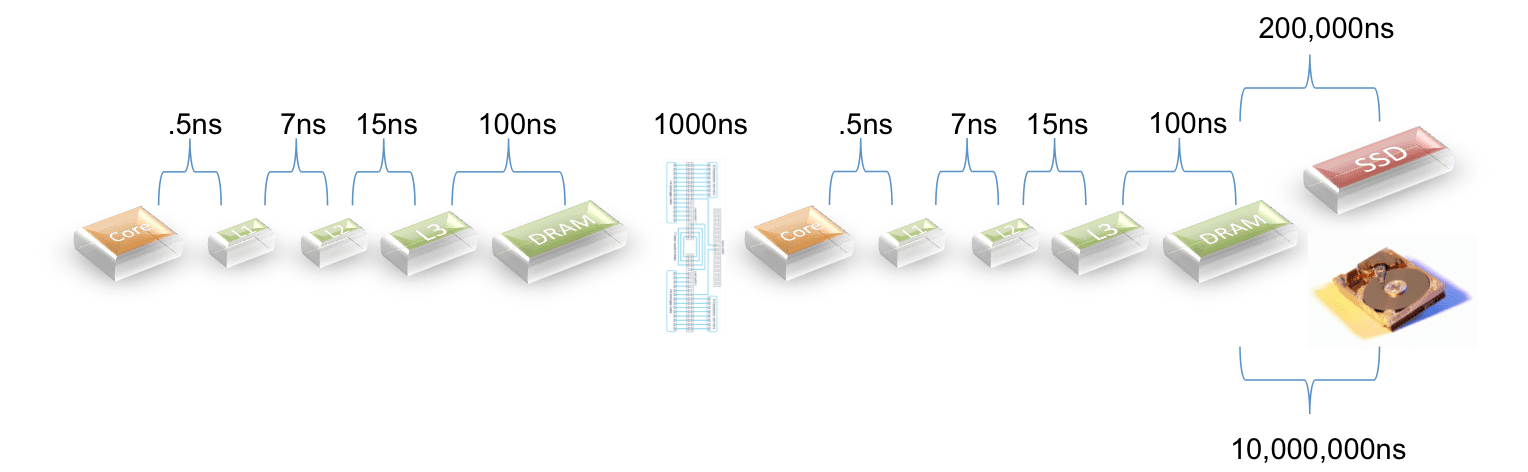
I recently pointed out some silliness published by Teradata to several SAP prospects. There is more nonsense that was sent and I’d like to take a moment to clear up these additional claims.
In their note to HANA prospects they used the following numbers from the paper SAP published here:
| # of Query Streams |
1 |
10 | 20 |
25 |
| # of Queries per Hour (Throughput) |
6,282 |
36,600 | 48,770 |
52,212 |
Teradata makes several claims from these numbers. First they claim that the numbers demonstrate a bottleneck that is tied to either the NUMA effect or to the SMP Knee Curve. This nonsense is the subject of a previous blog here.
For any database system as you increase the number of queries to the point where there is contention the throughput decreases. This is just common sense. If you have 10 cores and 10 threads and there is no contention then all threads run at the same speed as fast as possible. If you add an 11th thread then throughput falls off, as one thread has to wait for a core. As you add more threads the throughput falls further until the system is saturated and throughput flattens. Figure 1 is an example of the saturation curve you would expect from any system as the throughput flattens.


Teradata claims that these numbers reflect a scaling issue. This is a very strange claim. Teradata tests scaling by adding hardware, data, and queries in equal amounts to see if the query performance holds constant… or they add hardware and data to look for a correlation between the number of nodes and query performance… hoping that as the nodes increase the response time decreases. In fact Teradata scales well… as does HANA… But the hardware is constant in the HANA benchmark so there is no view into scaling at all. Let me emphasis this… you cannot say anything about scaling from the numbers above.
Teradata claims that they can extrapolate the saturation point for the system… this represents very bad mathematics. They take the four data points in the table and create an S curve like the one in Figure 1… except they invert it to show how throughput decreases as you move towards the saturation point… Figure 2 shows the problem.


If you draw a straight line through the curve using any sort of math you miss the long tail at the end. This is an approximation of the picture Teradata drew… but even in their picture you can see a tail forming… which they ignore. It is also questionable math to extrapolate from only four observations. The bottom line is that you cannot extrapolate the saturation point from these four numbers… you just don’t know how far out the tail will run unless you measure it.
To prove this is nonsense you just have to look here. It turns out that SAP publicly published these benchmark results in two separate papers and this second one has numbers out to 60 streams. Unsurprisingly at 60 streams HANA processed 112,602 queries per hour while Teradata told their customers that it would saturate well short of that… at 49,601 queries (they predicted that HANA would thrash and the number of queries/hour would fall back… more FUD).
Teradata is sending propaganda to their prospects with scary extrapolations and pronouncements of architectural bottlenecks in HANA. The mathematics behind their numbers is weak and their incorrect use of deep architectural terms demonstrates ignorance of the concepts. They are trying to create Fear, Uncertainty, and Doubt. Bad marketing… not architecture, methinks.