A 30 feet chunk of the cliff below the apartment building fell to Pacific Ocean. (Photo credit: Wikipedia)
Jason asked a great question in the comment section here… he asked… does Teradata’s Intelligent Memory erode HANA’s value proposition? Let me answer here in a more general way that is applicable to the general database space…
Every time a vendor puts more silicon between the CPU and the disk they will improve their performance (and increase their price). Does this erode HANA’s value proposition? Sure. Every advance by any vendor erodes every other vendor’s position.
To win business a new database product has to be faster than the competition. In my experience you have to be at least 30% faster to unseat the incumbent. If you are 50% faster you will win a lot of business. If you are 2x, 100%, faster you win nearly every time.
Therefore the questions are:
Did the Teradata announcement eliminate a set of competitors from reaching these thresholds when Teradata is the incumbent? Yup. It is very smart.
Does Intelligent Memory allow Teradata to reach these thresholds when they compete against another incumbent. Yup.
Did it eliminate HANA from reaching these thresholds when competing with Teradata? I do not think so… in fact I’m pretty sure it is not the case… HANA should still be way over the 2x threshold… but the reasons why will require a deeper dive… stay tuned.
In the picture attached a 30 foot chunk eroded… but Exadata still stands. Will it be condemned?
Note: Here is a commercial post on the SAP HANA blog site that describes at a high level why I think HANA retains a distinct architectural advantage.
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
Teradata Storage Rack (Photo credit: pchow98)
Summary
Despite my criticisms of some of their market positions (here, here, here, and here) Teradata provides the single best data warehouse platform in the market, hands-down. As an EDW, or data mart it is the best. It will be very competitive as an analytics mart and/or as an operational data store. It has a very complete eco-system of utilities and offers a robust set of Reliability, Availability, Serviceability, and Recoverability (RASR) features to make the eco-system solid. Performance is very good… Teradata should win more POCs than they lose… and they have become more competitive on price… so their price/performance is good if not great.
I recommend a POC for most customers in most cases… you can often save 20%-30% in a competitive situation.. but if you don’t have any special requirements… if you are building a standard BI/DW eco-system then Teradata would be the only vendor I would trust without a POC.
Where They Win
Now that they support columnar tables and columnar projection Teradata should win way more POCs than they lose (before columnar support they could lose to the column stores or to hybrids like Greenplum). The Teradata optimizer is very robust. It efficiently solves for a broad array of queries, and for a mixed workload that cuts across the data is many ways. This makes Teradata well-suited as the platform for an EDW.
Every RDBMS has a sweet spot where they win… so Teradata will not win every POC. But if you POC for an EDW and you prove with a full contingent of data, with queries that cut across the data in several ways, with a fair emulation of data loading, querying, loading , and querying… with a full workload… Teradata is tough to beat.
Where They Lose
The shared-nothing architecture is an imperfect fit on a single node… so other players can win smaller data warehouses that can fit on 1-2 nodes. In addition, they can be beat for very large configurations (1PB and above…) by Hadoop.
Teradata can be beat when the workload consists of very complex queries and/or where the problem to be solved requires fantastic response on a small number of CPU-intensive queries… this is a side-effect of spooling the intermediate results to a block device.
Teradata can be beat when data is trickled in at a high, continuous, rate.
Teradata can be beat when a query set goes through the data in a narrow way, using a single index or the equivalent, as might be the case for a data mart.
Teradata can be beat on price.
In the Market
For the reasons above, Teradata is the leader in the DW platform market. Recent competition from Exadata, Netezza, Greenplum, Vertica… and now HANA… has cut margins but not impacted business growth too much. Competitors have projected Teradata’s demise for 20 years now… but the product continues to set the standard.
As noted here, I believe that Hadoop will squeeze Teradata at the 1PB level and above…
My Guess at the Future
Teradata has three architectural challenges to address… and I suspect they will manage all three more-or-less.
First, the old architecture which was designed for very small DRAM configurations forces unnecessary I/O in violation of Gray and Putzolu’s Five Minute Rule (see here). This will be mitigated in the short-term by writing spool to SSD devices… and in the medium term by writing spool to NVRAM. If these mitigations are not sufficient then Teradata may have to consider re-engineering in a data flow scheme… but this will be tough.
Next, there are several advances in network technology coming in the next 2-3 years… and software defined networks will impact the space as well. ByNet may have served its purpose… providing Teradata with a significant edge for 20+ years… but Teradata may consider moving to an off-the-shelf network (see here).
Finally, a truly active data warehouse requires support for simultaneous OLTP and BI workloads… I would expect Teradata to build in the sort of hybrid OLTP/BI table capability now supported by both Vertica and HANA… and quasi-supported by Gemfire/Greenplum.
Teradata has some interesting business challenges as their margins shrink… and one of those challenges is that their expensive 3-person relationship/technical/industry sales team approach will face some pressure. But it is these sales teams that also provide Teradata an edge. They are the only databases vendor who can field team after team of veterans who understand both the technology and the vertical space.
If I were King of Teradata I might try to push downstream and build a configuration optimized for the low end. This would not be a high-margin hardware business but it would sell services and increase market share.
When I was at Greenplum… and now again at SAP… I ran into a strange logic from Teradata about query concurrency. They claimed that query concurrency was a good thing and an indicator of excellent workload management. Let’s look at a simple picture of how that works.
In Figure 1 we depict a single query on a Teradata cluster. Since each node is working in parallel the picture is representative no matter how many nodes are attached. In the picture each line represents the time it takes to read a block from disk. To make the picture simple we will show I/O taking only 1/10th of the clock time… in the real world it is slower.
Given this simplification we can see that a single query can only consume 10% of the CPU… and the rest of the time the CPU is idle… waiting for work. We also represented some I/O to spool files… as Teradata writes all intermediate results to disk and then reads them in the next step. But this picture is a little unfair to Greenplum and HANA as I do not represent spool I/O completely. For each qualifying row the data is read from the table on disk, written to spool, and then read from spool in the subsequent step. But this note is about concurrency… so I simplified the picture.
Figure 2 shows the same query running on Greenplum. Note that Greenplum uses a data flow architecture that pushes tuples from step to step in the execution plan without writing them to disk. As a result the query completes very quickly after the last tuple is scanned from the table.
Let me say again… this story is about CPU utilization, concurrency, and workload management… I’m not trying to say that there are not optimizations that might make Teradata outperform Greenplum… or optimizations that might make Greenplum even faster still… I just want you to see the impact on concurrency of the spool architecture versus the data flow architecture.
Note that on Greenplum the processors are 20% busy in the interval that the query runs. For complex queries with lots of steps the data flow architecture provides an even more significant advantage to Greenplum. If there are 20 steps in the execution plan then Teradata will do spool I/O, first writing then reading the intermediate results while Greenplum manages all of the results in-memory after the initial reads.
In Figure 3 we see the impact of having the data in-memory as with HANA or TimeTen. Again, I am ignoring the implications of HANA’s columnar orientation and so forth… but you can clearly see the implications by removing block I/O.
Now let’s look at the same pictures with 2 concurrent queries. Let’s assume no workload management… just first in, first out.
In Figure 4 we see Teradata with two concurrent queries. Teradata has both queries executing at the same time. The second query is using up the wasted space made available while the CPUs wait for Query 1’s I/O to complete. Teradata spools the intermediate results to disk; which reduces the impact on memory while they wait. This is very wasteful as described here and here (in short, the Five Minute Rule suggests that data that will be reused right away is more economically stored in memory)… but Teradata carries a legacy from the days when memory was dear.
But to be sure… Teradata has two queries running concurrently. And the CPU is now 20% busy.
Figure 5 shows the two-query picture for Greenplum. Like Teradata, they use the gaps to do work and get both queries running concurrently. Greenplum uses the CPU much more efficiently and does not write and read to spool in between every step.
In Figure 6 we see HANA with two queries. Since one query consumed all of the CPU the second query waits… then blasts through. There is no concurrency… but the work is completed in a fraction of the time required by Teradata.
If we continue to add queries using these simple models we would get to the point where there is no CPU available on any architecture. At this point workload management comes into play. If there is no CPU then all that can be done is to either manage queries in a queue… letting them wait for resources to start… or start them and let them wastefully thrash in and out… there is really no other architectural option.
So using this very simple depiction eventually all three systems find themselves in the same spot… no CPU to spare. But there is much more to the topic and I’ve hinted about these in previous posts.
Starting more queries than you can service is wasteful. Queries have to swap in and out of memory and/or in and out of spool (more I/O!) and/or in and out of the processor caches. It is best to control concurrency… not embrace it.
Running virtual instances of the database instead of lightweight threads adds significant communications overhead. Instances often become unbalanced as the data returned makes the shards uneven. Since queries end when the slowest instance finishes it’s work this can reduce query performance. Each time you preempt a running query you have to restore state and repopulate the processor’s cache… which slows the query by 12X-20X. … Columnar storage helps… but if the data is decompressed too soon then the help is sub-optimal… and so on… all of the tricks used by databases and described in these blogs count.
But what does not count is query concurrency. When Teradata plays this card against Greenplum or HANA they are not talking architecture… it is silliness. Query throughput is what matters. Anyone would take a system that processes 100,000 queries per hour over a system that processes 50,000 queries per hour but lets them all run concurrently.
I’ve been picking on Teradata lately as they have been marketing hard… a little too hard. Teradata is a fine system and they should be proud of their architecture and their place in the market. I am proud to have worked for them. I’ll lay off for a while.
I recently pointed out some silliness published by Teradata to several SAP prospects. There is more nonsense that was sent and I’d like to take a moment to clear up these additional claims.
In their note to HANA prospects they used the following numbers from the paper SAP published here:
Teradata makes several claims from these numbers. First they claim that the numbers demonstrate a bottleneck that is tied to either the NUMA effect or to the SMP Knee Curve. This nonsense is the subject of a previous blog here.
For any database system as you increase the number of queries to the point where there is contention the throughput decreases. This is just common sense. If you have 10 cores and 10 threads and there is no contention then all threads run at the same speed as fast as possible. If you add an 11th thread then throughput falls off, as one thread has to wait for a core. As you add more threads the throughput falls further until the system is saturated and throughput flattens. Figure 1 is an example of the saturation curve you would expect from any system as the throughput flattens.
There are some funny twists to this, though. If you are an IMDB then each query can use 100% of a core. If you are multi-threaded IMDB then each query can use 100% of all cores. If you are a disk-based system then you give up the CPU to another query while you wait for I/O… so throughput falls. I’ll address these twists in a separate blog… but you will see a hint at the issue here.
Teradata claims that these numbers reflect a scaling issue. This is a very strange claim. Teradata tests scaling by adding hardware, data, and queries in equal amounts to see if the query performance holds constant… or they add hardware and data to look for a correlation between the number of nodes and query performance… hoping that as the nodes increase the response time decreases. In fact Teradata scales well… as does HANA… But the hardware is constant in the HANA benchmark so there is no view into scaling at all. Let me emphasis this… you cannot say anything about scaling from the numbers above.
Teradata claims that they can extrapolate the saturation point for the system… this represents very bad mathematics. They take the four data points in the table and create an S curve like the one in Figure 1… except they invert it to show how throughput decreases as you move towards the saturation point… Figure 2 shows the problem.
If you draw a straight line through the curve using any sort of math you miss the long tail at the end. This is an approximation of the picture Teradata drew… but even in their picture you can see a tail forming… which they ignore. It is also questionable math to extrapolate from only four observations. The bottom line is that you cannot extrapolate the saturation point from these four numbers… you just don’t know how far out the tail will run unless you measure it.
To prove this is nonsense you just have to look here. It turns out that SAP publicly published these benchmark results in two separate papers and this second one has numbers out to 60 streams. Unsurprisingly at 60 streams HANA processed 112,602 queries per hour while Teradata told their customers that it would saturate well short of that… at 49,601 queries (they predicted that HANA would thrash and the number of queries/hour would fall back… more FUD).
Teradata is sending propaganda to their prospects with scary extrapolations and pronouncements of architectural bottlenecks in HANA. The mathematics behind their numbers is weak and their incorrect use of deep architectural terms demonstrates ignorance of the concepts. They are trying to create Fear, Uncertainty, and Doubt. Bad marketing… not architecture, methinks.
Teradata is circulating a document to customers that claims that the numbers SAP has published in its 100TB PoC white paper (here) demonstrates that HANA suffers from scaling issues associated with the NUMA-effect. The document is so annoyingly inaccurate that I have to respond.
NUMA stands for non-uniform-memory-access. This describes an architecture whereby each core in a multi-core system has some very fast local memory accessed directly through a memory bus… but has access to every other core’s local memory through a “remote” access hop over another fast bus. In the case of Intel Xeon servers the other fast bus is know as the QPI bus. “Non-uniform” means that all memory access are not equal… a remote access over the QPI bus is slower than access over the memory bus.
The first mistake in the Teradata document is where they refer to the problem as the “SMP Knee Curve”. SMP stands for symmetric multi-processing… an architecture where multiple cores share the same memory bus. The SMP Knee Curve describes the problem when too many cores are contending for the same bus. HANA is not certified to run on an SMP system. The 100TB PoC described above is not run on an SMP system. When describing issues you might expect Teradata to at least associate the issue with the correct hardware architecture.
The NUMA-effect describes problems scaling processors within a single NUMA node. Those issues can impact the ability to continuously add cores as memory locking issues across the QPI bus slow the system. There are ways to mitigate this problem, though (see here for some examples of how to code around the problem).
Of course HANA, which built an in-memory system with NUMA as a target from the start… has built in these NUMA mitigations. In fact, HANA is designed deeper still using special techniques to keep the processor caches filled and to invoke special-purpose SIMD instructions. HANA is built so close to the hardware that processor cycles that are unused due to cache misses but show up as processor busy are avoided (in other words, HANA will get more work done on a 100% CPU busy system than other software that will show 100% CPU busy). But Teradata chose to ignore this deep integration… or they were unaware of these techniques.
Worse still, the problem Teradata calls out… shouts out… is about scaling over 100 nodes in a shared-nothing configuration. The NUMA-effect has nothing at all to do with scale out across nodes. It is an issue within a single node. For Teradata to claim this is silliness at best. It is especially silly since the shared-nothing architecture upon which HANA is built is the same architecture Teradata uses.
The twists Teradata applies to the numbers are equally absurd… but I’ll stop here and hope that the lack of understanding they exhibit in throwing around terms like “SMP Knee Curve” and “NUMA-effect” will cast enough doubt that the rest of their marketing FUD will be suspect. Their document is surely not about architecture… it is weak marketing… you can see more here…
Here is an attempt to build a Price/Performance model for several data warehouse databases.
Added on February 21, 2013: This attempt is very rough… very crude… and a little too ambitious. Please do not take it too literally. In the real world Greenplum and Teradata will match or exceed the price/performance of Exadata… and the fact that the model does not show this exposes the limitations of the approach… but hopefully it will get you thinking… – Rob
For price I used some $$/Terabyte numbers scattered around the internet. They are not perfect but they are close enough to make the model interesting. I used:
Of these numbers the one that may be the furthest off is the HANA number. This is odd since I work for SAP… but I just could not find a good number so I picked a big number to see how the model came out. Please, for any of these numbers provide a comment and I’ll adjust.
For each product I used the high performance product rather than the product with large capacity disks…
I used latency as a stand-in for performance. This is not perfect either… but it is not too bad. I’ll try again some other time and add data transfer time to the model. Note that I did not try to account for advantages and disadvantages that come from the software… so the latency associated with I/O to spool/work files is not counted… use of indexes and/or column store is not counted… compression is not counted. I’ll account for some of this when I add in transfer times.
I did try to account for cache hits when there is SSD cache in the configuration… but I did not give HANA credit for the work done to get most data from the processor caches instead of from DRAM.
For network latency I just assumed one round trip for each product…
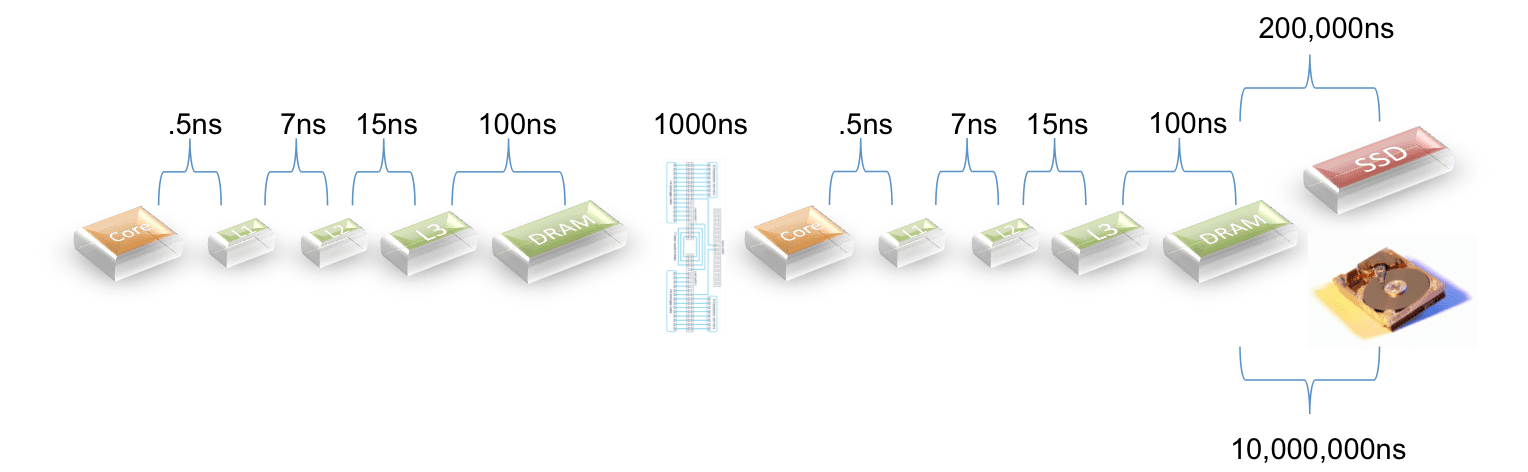
For latencies I used the picture below:
The exception is that for products that use PCIe to access SSDs I cut the latency by 1/3 based on some input from a vendor. I could not find details on the latency for Teradata’s Bynet so I assumed that it is comparable with Infiniband and the newest 10GigE switches.
Here is what I came up with:
Database
Total Latency(ns)
Price/Performance
Delta
HANA
90
1,800
–
HANA (2 nodes)
1190
23,800
13x
Exadata X3
2,054,523
13,559,854
7533x
Teradata
4,121,190
27,199,854
15111x
Greenplum
10,001,190
30,003,570
16669x
I suppose that if a model seems to reflect reality then it is useful?
HANA has the lowest latency because it is in-memory. When there are two nodes a penalty is paid for crossing the network… this makes sense.
Exadata does well because the X3 product has SSD cache and I assumed an 80% hit ratio.
Teradata does a little worse because I assumed a lower hit ratio (they have less SSD per TB of data).
Greenplum does worse as they do all I/O against disks.
Note the penalty paid whenever you have to go to disk.
Let me say again… this model ignores lots of software features that would affect performance… but it is pretty interesting as a start…
HANA vs. Teradata – Part 1: This is a response to some poor thinking posted by Teradata. There is some new content that could be worth a look.
HANA vs. Teradata – Part 2: This continues the response… but it is a rehash of the post here on the rational economics of in-memory databases. Frankly, I had just reread the Teradata posts and wrote this while still annoyed… as a result it is a little flip and despite the junk posted by Teradata I might have shown them a little more respect…
Exalytics vs. Exadata: This post suggests some oddness in Oracle’s positioning of Exalytics and Exadata… maybe worth a look.
As you look at the enterprise RDBMS marketplace today you will find something shocking… almost every product in the market is built based on designs and concepts that are over thirty years old. IBM’s System R grew into DB2 and influenced Oracle before 1980. Ingres, developed before 1980, became Postgres which became Netezza and Greenplum and more. Teradata was a fresh start… around 1980.
This is not a bad thing in its own right… but imagine the hardware architectures these systems were designed and optimized for. Maybe DB2 was built for a multi-core mainframe… maybe Oracle too… maybe. Memory was tiny… so memory management was important and memory was used sparingly. Data sizes were tiny. Consider the fact that Teradata named the company based on the belief that someday way beyond the planning horizon some customers might get to a terabyte of data.
The reality is that these old designs are inefficient. They have hacked the old code to continuously extend their products. I mean this as a compliment. It is not trivial engineering to find tweaks and tack-ons that make old code work on new hardware architectures. Teradata and Netezza and Greenplum designed ways to use multiple address spaces to take advantage of multiple cores. Oracle tacked-on a shared-nothing I/O subsystem to a shared-everything architecture to stretch.
But these hacks are not efficient.
Yale is working on some new-new stuff (see here). HANA is based on a completely different design (see here). The NoSQL vendors have bent the ACID-tested rules, if not always the fundamental approaches.
I can’t help but believe that in one of these new approaches is a path forward.
If you would like to read some history of the start here is a cool link.
I have just written a commercial blog for work refuting some silliness from Teradatahere and here. Since some of this refutes an argument that targets in-memory database architecture in general it is worth restating the case here.
The Teradata argument states that since data warehouses are growing 40% per year and the cost of memory is dropping only 20% per year that the economics of in-memory databases (IMDB) is “irrational” and that the whole IMDB idea is “hype”. Let’s have a look at the Teradata argument…
First, let’s imagine a 100TB data warehouse that is built today… and let’s imagine that it is economically reasonable today. There is an explicit argument for this here and an implicit argument here… but since the Teradata argument says that the IMDB economics get worse over time it really doesn’t matter where we start. If Teradata is right then time will tell.
Now lets apply Teradata’s economics for a couple of years…
Next year, according to Teradata, the data warehouse will have grown to 140TB and the cost of memory will have dropped 20%… making IMDB more economic. The following year your data warehouse will have grown to about 200TB and the cost of memory will have dropped another 20% making the IMDB even more cost-effective. The following year the DW will be 280TB and the cost of memory will have dropped another 20% making it even more cost-effective.
In other words, the Teradata sound bite is silly. It has emotional appeal… but it is nonsense.
But there is more. Moore’s Law does not say that price will fall 2X every 2 years… it suggests that performance (actually transistor density) will improve 2X every two years. The fact is that memory prices are falling AND memory speeds are improving… and the gap between memory speeds and disk speeds is increasing. So the gap in price/performance of an IMDB vs. a disk-based system is increasing exponentially.
These are the economics that matter… and these are the economics that are driving Teradata to put silicon in-between their disks and their processors.
Teradata’s argument is marketing, not architecture.
I have promised not to promote HANA heavily on this site… and I will keep that promise. But I want to share something with you about the HANA architecture that is not part of the normal marketing in-memory database (IMDB) message: HANA is parallel from its foundation.
What I mean by that is that when a query is executed in-memory HANA dynamically shards the data in-memory and lets each core start a thread to work on its shard.
Other shared-nothing implementations like Teradata and Greenplum, which are not built on a native parallel architecture, start multiple instances of the database to take advantage of multiple cores. If they can start an instance-per-core then they approximate the parallelism of a native implementation… at the cost of inter-instance communication. Oracle, to my knowledge, does not parallelize steps within a single instance… I could be wrong there so I’ll ask my readers to help?
As you would expect, for analytics and complex queries this architecture provides a distinct advantage. HANA customers are optimizing price models sub-second in-real-time with each quote instead of executing a once-a-week 12-hour modeling job.
June 11, 2013: You can find a more complete and up-to-date discussion of this topic here… – Rob
As you would expect HANA cannot yet stretch into the petabyte range. The current HANA sweet spot is for warehouses or marts is in the sub-TB to 20TB range.