@henryccook made an interesting point regarding Netezza workload management this morning… He suggested that once a SPU is engaged by a snippet the work must be completed before another snippet can start. To say this another way… a SPU has no OS and cannot save context for a snippet and start another… then return.
If this is true it means that if a long-running snippet starts… a full file scan of a fact table with no use of the zone map… then that snippet will lock out others queries until it completes.
This is not a very fine-grained approach to workload management and we would expect it to cause difficulties.
Can anyone confirm that this is true? It feels right from an architectural perspective…
Here is an attempt to build a Price/Performance model for several data warehouse databases.
Added on February 21, 2013: This attempt is very rough… very crude… and a little too ambitious. Please do not take it too literally. In the real world Greenplum and Teradata will match or exceed the price/performance of Exadata… and the fact that the model does not show this exposes the limitations of the approach… but hopefully it will get you thinking… – Rob
For price I used some $$/Terabyte numbers scattered around the internet. They are not perfect but they are close enough to make the model interesting. I used:
Of these numbers the one that may be the furthest off is the HANA number. This is odd since I work for SAP… but I just could not find a good number so I picked a big number to see how the model came out. Please, for any of these numbers provide a comment and I’ll adjust.
For each product I used the high performance product rather than the product with large capacity disks…
I used latency as a stand-in for performance. This is not perfect either… but it is not too bad. I’ll try again some other time and add data transfer time to the model. Note that I did not try to account for advantages and disadvantages that come from the software… so the latency associated with I/O to spool/work files is not counted… use of indexes and/or column store is not counted… compression is not counted. I’ll account for some of this when I add in transfer times.
I did try to account for cache hits when there is SSD cache in the configuration… but I did not give HANA credit for the work done to get most data from the processor caches instead of from DRAM.
For network latency I just assumed one round trip for each product…
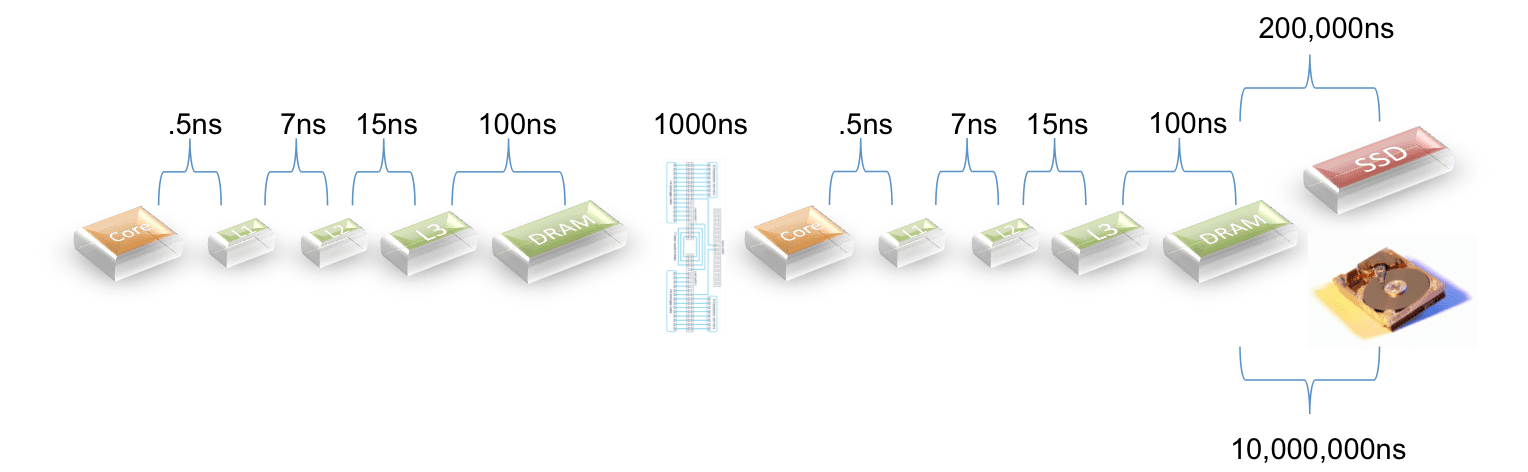
For latencies I used the picture below:
The exception is that for products that use PCIe to access SSDs I cut the latency by 1/3 based on some input from a vendor. I could not find details on the latency for Teradata’s Bynet so I assumed that it is comparable with Infiniband and the newest 10GigE switches.
Here is what I came up with:
Database
Total Latency(ns)
Price/Performance
Delta
HANA
90
1,800
–
HANA (2 nodes)
1190
23,800
13x
Exadata X3
2,054,523
13,559,854
7533x
Teradata
4,121,190
27,199,854
15111x
Greenplum
10,001,190
30,003,570
16669x
I suppose that if a model seems to reflect reality then it is useful?
HANA has the lowest latency because it is in-memory. When there are two nodes a penalty is paid for crossing the network… this makes sense.
Exadata does well because the X3 product has SSD cache and I assumed an 80% hit ratio.
Teradata does a little worse because I assumed a lower hit ratio (they have less SSD per TB of data).
Greenplum does worse as they do all I/O against disks.
Note the penalty paid whenever you have to go to disk.
Let me say again… this model ignores lots of software features that would affect performance… but it is pretty interesting as a start…
There is a persistent myth, like a persistent cough, that claims that in-memory databases lose data when a hardware failure takes down a node because memory is volatile and non-persistent. This myth is marketing, not architecture.
Most RDBMS products: including Oracle, TimesTen, and HANA; have three layers where data exists: in-memory (think SGA for Oracle), in the log, and on disk. The normal process goes like this:
A write transaction arrives
The transaction is written to the log file and committed… this is a very quick process with 1 sequential I/O… quicker still if the log file is on a SSD device
The query updates the in-memory layer; and
After some time passes, saves the in-memory data to disk.
Recovery for these databases is easy to understand:
If a hardware failure occurs and #1 but before #2 the transaction has not been committed and is lost.
If a hardware failure occurs after #2 but before #3 the transaction is committed and the database is rebuilt when the node restarts from the log file.
If a hardware failure occurs after #3 but before #4 the same process occurs… the database is rebuilt when the node restarts from the log file.
If a hardware failure occurs after #4 the database is rebuilt from the disk copy.
“Unlike traditional distributed databases, SQLFire does not use write-ahead logging for transaction recovery in case the commit fails during replication or redundant updates to one or more members. The most likely failure scenario is one where the member is unhealthy and gets forced out of the distributed system, guaranteeing the consistency of the data. When the failed member comes back online, it automatically recovers the replicated/redundant data set and establishes coherency with the other members. If all copies of some data go down before the commit is issued, then this condition is detected using the group membership system, and the transaction is rolled back automatically on all members.”
Redundant in-memory data optimizes transaction throughput but requires twice the memory. There are options to persist data to disk… but these options provide an approach that is significantly slower than the write-ahead logging used by TimesTen and HANA (and Oracle and Postgres, and …).
The bottom line: IMDBs are designed in the same manner as other, disk-based, DBMSs. They guarantee that comitted data is safe… everytime.
P.S.
See here for how these DBMSs compare when a BI/analytic workload is applied.
As you may have noticed I’m looking at in-memory databases (IMDB) these days… Here are some quick architectural observations on VMWare‘s SQLFire, Oracle’s Exalytics and TimesTen offerings, and SAP HANA.
It is worth noting up front that I am looking to see how these products might be used to build a generalized data mart or a data warehouse… In other words I am not looking to compare them for special case applications. This is important because each of these products has some extremely cool features that allow them to be applied to application-specific purposes with a narrow scope of data and queries… maybe in a later blog I can try to look at some narrow use-cases.
Further, to make this quick blog tractable I am going to assume that the mart/dw problem to be solved requires more data than can fit on one server node… and I am going to ignore features that let queries access data that resides on disk… in-memory or bust.
Finally I will assume that the SQL dialect supported is sufficient and not drill into details there. I will look at architecture not SQL features…
Simply put I am going to look at a three characteristics:
Will the architecture support ad hoc queries?
Does the architecture support scale-out?
Can we say anything with regards to price/performance expectations?
Exalytics is a smart-aggregate store that sits over an Oracle database to offload aggregate query workload (see my previous post here or the Rittman Mead post here which declares: “Oracle Exalytics uses a specially enhanced version of Oracle TimesTen, Oracle’s in-memory database, to cache commonly used aggregates used in dashboards, analyses and other BI objects.” Exalytics does not support a scale-out shared-nothing architecture but it can scale up by adding nodes with new aggregate data. Queries access data within the aggregate structure and it is not possible to join to data off the Exalytics node… so ad hoc is out. Within these limits, which preclude Exalytics from being considered as a general platform for a mart or warehouse, Exalytics provides dictionary-based compression which should provide around 5X compression to reduce the amount of memory required and reduce the amount of hardware required.
TimesTen can do more. It is a general RDBMS. But it was designed for OLTP. I assume that the reason that Oracle has not rolled it out as a general-purpose data mart or data warehouse has to do with constraints that grow from those OLTP architectural roots. For example, BI queries run longer and require more data than a OLTP query… and even with data in-memory temporary storage is required for each query… and memory utilization is a product of the amount of data required and the amount of time the data has to inhabit memory… so BI queries put far more pressure on an in-memory DBMS. There are techniques to mitigate this… but you have to build the techniques in from the ground up.
I imagine that this is why TimesTen works for Exalytics, though. A OLAP query against a pre-aggregated cube does not graze an entire mart or warehouse. It is contained and “small data” (for my wacky take re: Exalytics and Exadata see here).
TimeTen is not sharded… so scalability is an issue. Oracle gets around this nicely by allowing you to partition data across instances and have the application route queries to the appropriate server. But this approach will not support joins across partitions so it severely limits scalability in a general-purpose mart or warehouse.
SQLFire is a very interesting new product built on top of Gemfire… and therefore mature from the start. SQLFire is more scalable than TimesTen/Exalytics. It supports sharded data in a cluster of servers. But SQLFire has the limitation that it cannot join data across shards (they call them partitions… see here) so it will be hard to support ad hoc queries… They provide the ability to replicate tables to support any sort of joins. If, for example, you replicate small dimension tables to coexist with sharded fact tables all joins are supported. This solution is problematic if you have multiple fact tables which must be joined… and replication of data uses more memory… but SQLFire has the foundation in place to become BI-capable over time.
Performance in an in-memory database comes first and foremost from eliminating disk I/O. All three IMDB product provide this capability. Then performance comes from the efficient use of compression. TimeTen incorporates Oracles dictionary-based “columnar” compression (I so hate this term… it is designed to make people think that Oracle products are sort-of columnar… but so far they are not). Then performance comes from columnar projection… the ability to avoid touching all data in a row to process a query. Neither TimesTen nor SQLFire are columnar databases. Then performance comes from parallel execution. Neither TimesTen nor SQLFire can involve all cores on a single query to my knowledge.
Price comes from compression as well. The more highly compressed the data is the less memory required to store it. Further, if data can be used without decompressing it, then less working memory is required. As noted, TimesTen has a compression capability. SQLFire does not appear to compress data. Neither can use compressed data. Note that 2X compression cuts the amout of memory/hardware required in half or more… 4X cuts it to a quarter… and so on. So this is significant.
Now for some transparency… I started the research for this blog, and composed a 1st draft, last Spring while I was at EMC Greenplum. I am now at SAP working with HANA. So… I will not go into HANA at great length… but I will point out that: HANA fully supports a shared-nothing architetcture… so it is fully scalable; HANA is fully parallel and able to use all cores for each query; HANA fully supports columnar tables so it provides deep compression and the ability to use the compressed data in execution. This is not remarkable as HANA was designed from the bottom up to support both BI and OLTP workloads while TimesTen and SQLFire started from a purely OLTP architectural foundation.
HANA vs. Teradata – Part 1: This is a response to some poor thinking posted by Teradata. There is some new content that could be worth a look.
HANA vs. Teradata – Part 2: This continues the response… but it is a rehash of the post here on the rational economics of in-memory databases. Frankly, I had just reread the Teradata posts and wrote this while still annoyed… as a result it is a little flip and despite the junk posted by Teradata I might have shown them a little more respect…
Exalytics vs. Exadata: This post suggests some oddness in Oracle’s positioning of Exalytics and Exadata… maybe worth a look.
English: Larry Ellison lecturing during Oracle OpenWorld, San Francisco 2010 עברית: לארי אליסון מרצה בכנס אורל בסאן פרנסיסקו (Photo credit: Wikipedia)
Wikipedia defines computer memory as:
In computing, memory refers to the physical devices used to store programs (sequences of instructions) or data (e.g. program state information) on a temporary or permanent basis for use in a computer or other digitalelectronic device. The term primary memory is used for the information in physical systems which are fast (i.e. RAM), as a distinction from secondary memory, which are physical devices for program and data storage which are slow to access but offer higher memory capacity. Primary memory stored on secondary memory is called “virtual memory“.
To a computer program like a DBMS, memory is a resource allocated using commands like malloc() and calloc(). Note that these commands allocate primary memory using the definition above. From this you should conclude that an in-memory DBMS (IMDB) is a system that puts all of its data into memory allocated by the database program.
In their announcements this week Oracle states (here) that Exadata 3 is an in-memory database machine and Larry Ellison said. “Everything is in memory. All of your databases are in-memory. You virtually never use your disk drives. Disk drives are becoming passe. They’re good at storing images and a lot of data we don’t access very often.”
But their definition of in-memory includes SSD devices that are not directly addressable by the DBMS. In fact they use 22TB of SSDs and 4TB of DRAM. The SSDs are a cache sitting between the DBMS and disk storage. They are storage according to Wikipedia.
Exadata 3 is not an in-memory database machine. It takes more than lots of hardware to make a DBMS an in-memory DBMS.
As you look at the enterprise RDBMS marketplace today you will find something shocking… almost every product in the market is built based on designs and concepts that are over thirty years old. IBM’s System R grew into DB2 and influenced Oracle before 1980. Ingres, developed before 1980, became Postgres which became Netezza and Greenplum and more. Teradata was a fresh start… around 1980.
This is not a bad thing in its own right… but imagine the hardware architectures these systems were designed and optimized for. Maybe DB2 was built for a multi-core mainframe… maybe Oracle too… maybe. Memory was tiny… so memory management was important and memory was used sparingly. Data sizes were tiny. Consider the fact that Teradata named the company based on the belief that someday way beyond the planning horizon some customers might get to a terabyte of data.
The reality is that these old designs are inefficient. They have hacked the old code to continuously extend their products. I mean this as a compliment. It is not trivial engineering to find tweaks and tack-ons that make old code work on new hardware architectures. Teradata and Netezza and Greenplum designed ways to use multiple address spaces to take advantage of multiple cores. Oracle tacked-on a shared-nothing I/O subsystem to a shared-everything architecture to stretch.
But these hacks are not efficient.
Yale is working on some new-new stuff (see here). HANA is based on a completely different design (see here). The NoSQL vendors have bent the ACID-tested rules, if not always the fundamental approaches.
I can’t help but believe that in one of these new approaches is a path forward.
If you would like to read some history of the start here is a cool link.
I have just written a commercial blog for work refuting some silliness from Teradatahere and here. Since some of this refutes an argument that targets in-memory database architecture in general it is worth restating the case here.
The Teradata argument states that since data warehouses are growing 40% per year and the cost of memory is dropping only 20% per year that the economics of in-memory databases (IMDB) is “irrational” and that the whole IMDB idea is “hype”. Let’s have a look at the Teradata argument…
First, let’s imagine a 100TB data warehouse that is built today… and let’s imagine that it is economically reasonable today. There is an explicit argument for this here and an implicit argument here… but since the Teradata argument says that the IMDB economics get worse over time it really doesn’t matter where we start. If Teradata is right then time will tell.
Now lets apply Teradata’s economics for a couple of years…
Next year, according to Teradata, the data warehouse will have grown to 140TB and the cost of memory will have dropped 20%… making IMDB more economic. The following year your data warehouse will have grown to about 200TB and the cost of memory will have dropped another 20% making the IMDB even more cost-effective. The following year the DW will be 280TB and the cost of memory will have dropped another 20% making it even more cost-effective.
In other words, the Teradata sound bite is silly. It has emotional appeal… but it is nonsense.
But there is more. Moore’s Law does not say that price will fall 2X every 2 years… it suggests that performance (actually transistor density) will improve 2X every two years. The fact is that memory prices are falling AND memory speeds are improving… and the gap between memory speeds and disk speeds is increasing. So the gap in price/performance of an IMDB vs. a disk-based system is increasing exponentially.
These are the economics that matter… and these are the economics that are driving Teradata to put silicon in-between their disks and their processors.
Teradata’s argument is marketing, not architecture.
OLAP searches a set of pre-aggregated data… a cube. If the cube is large enough that you don’t bump into the edges you might think that your search is ad hoc… but that is an illusion. The set is prescribed not ad hoc.
In the 1980’s we sent paper reports out… they were moved on a pallet with a fork-lift. The reports aggregated key metrics to many levels in a hierarchy sliced and diced across many dimensions. Today we take the lines off the reports and store them digitally in a cube and provide tools to let users navigate the cube to build their reports. What they build looks, to a large extent, like the reports from the 80’s.
Data warehousing provides more data and better data… so there are more cubes, more dimensions, more reports… and hopefully more business intelligence. But these reports provide 1980’s quality business intelligence on a screen instead of on paper… bounded by the OLAP cube.
When you hear folks talk about data science and data mining and advanced analytics and optimization… they are talking about advanced mathematical treatment of the data… know that this is going to require technology that is beyond the capabilities of a OLAP engine.
Exalytics is a OLAP engine. Here are some Exalytics use cases from a proponent. They are about OLAP dashboards… good stuff… but hardly advanced analytics. Oracle says that Exalytics is engineered for Extreme Analytics. If we agree that “extreme” analytics is not in any way advanced… then I agree.