My contacts from Strata read my post here and provided me with the following information:
The performance numbers quoted for Greenplum HAWQ versus HIVE and Impala used Greenplum tables implemented over HDFS. In other words, this data is unreadable from outside of the Greenplum database… unreadable by any other program in the Hadoop eco-system… a proprietary format. If the tests were re-run using the same open data structures used by HIVE and Impala you would find the performance of HAWQ to be closer to, or worse than, those Hadoop components.
The HAWQ performance numbers quoted represent a 2X-3X performance degradation over the same benchmark run on the native Greenplum RDBMS.
Again… this is from a credible source… but please consider this a rumor… and view this report, and the associated Greenplum marketing… with an appropriate measure of engineering skepticism.
Greenplum is a fantastic product… if I assume the report to be true then I do not understand why are they doing this… what use case is solved by a 300% performance degradation accessing proprietary data in HDFS? Remember, you could put Greenplum in the same cluster as Hadoop (UAP) and query everything HAWQ could query without the performance degradation. I just do not see the point? Could someone from GP comment and help my readers and myself here?
First, from a technical standpoint I like the Greenplum-on-HDFS HAWQ offering. It looks like the GP Team replaced XFS with HDFS and added some native support for several HDFS file types. I will say more on this soon.
But I would like to weigh-in on the question raised by HortonWorks here… is HAWQ Hadoop? And I have a question towards the end…
Let me propose an analogy: Hadoop is an eco-system of open source components much like LINUX is an eco-system of open source components. If you think the analogy apt, then HAWQ on HDFS is not Hadoop any more than Microsoft Internet Explorer on LINUX is LINUX. Hive is open source and part of the Hadoop eco-system… as is Impala. Firefox is open source and part of the LINUX eco-system. HAWQ is not Hadoop.
The HortonWorks link points out that Greenplum is not engaged in the Hadoop eco-system as a contributor. They also quote Greenplum as saying that they have 300 developers working on Hadoop. Well… if HAWQ is part of Hadoop and HAWQ is the Greenplum database on HDFS then they have 300 developers on Hadoop. But if, as I suggested, HAWQ is not Hadoop then the number of Greenplum developers on Hadoop might be less. I bumped into a long-time Greenplum employee at Strata who told me that HAWQ was a skunkworks project with 4-5 developers max. This comes from a credible source… but it is still rumor-quality… so take it with a grain of salt.
The bottom line is that Greenplum has marketed very aggressively. They fuzz the definition of Hadoop to claim their commercial database offering running on Hadoop is therefore “Hadoop”. They fuzz the definition of developers working on Hadoop based on this first fuzz.
But does it matter? Greenplum will read and process data stored in HDFS faster than any other SQL-based engine. That is worth something.
But what is it worth? I’m fairly certain that the Greenplum databases will run faster off of Hadoop on XFS than in Hadoop… maybe significantly faster. So the reason for Greenplum on HDFS is faster SQL access to data in HDFS files.
This leads me to my question. I wonder… were the performance numbers quoted, showing a significant performance advantage over both HIVE and Impala, based on queries executed against the Greenplum proprietary table formats or against the same native HDFS file types read by HIVE? If they ran against Greenplum tables then I wonder what the real apples-to-apples comparison would show? Note that I am not being cynical here… I do not know how the tests were set up… only that Greenplum was fast. But if as I said: ” the reason for Greenplum on HDFS is faster SQL access to data in HDFS files” and the data was in Greenplum file structures accessible only by Greenplum then there is little reason left.
I also wonder if it matters because HIVE and Impala will improve their performance significantly over the next 12-24 months. The sheer amount of human R&D being expended here will allow these SQL engines to catch, or nearly catch, HAWQ in performance. If there is any gap left, the price and the community of open source offerings will defeat HAWQ in the market.
As I have suggested here… there is no apparent commercial opportunity competing against Hadoop at this point. I suggested here that Hadoop would eat Greenplum if they stuck to the analytics space and offered both products… effectively competing with themselves. This new strategy is not likely to work in the medium or long run. Greenplum is, indeed, all-in on Hadoop… but without a winning hand.
March 10: See here for the answers to my questions… – Rob
March 12: See here for a rethink on this subject… – Rob
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
From a technical perspective, Greenplum is my favorite data warehouse database. Built on the same architecture as Teradata (see here), the Greenplum team was able to extend the core of Postgres… first building out a shared-nothing architecture and then adding feature after feature… putting the heat on the other major players. Greenplum was the first row-based RDBMS to add full columnar support… and their data-loading capability is second-to-none.
Oddly they do not want to be in the data warehouse space. Their recent announcement (here) does not include any reference to data warehousing or business intelligence. The tweets from @Greenplum, the Greenplum website, and all things marketing are focussed on analytics and/or Hadoop. Even their page on data warehousing (here) has no articles on data warehousing. It is just not their target market. That is fine… the product is still a great EDW platform… but it is a worry.
Where They Win
The reason they target analytics is because they excel there. If your warehouse workload clogs because of big, complex, queries… Greenplum can win the day. Their data flow architecture, which keeps tuples moving from execution step to execution step without writing to spool provides them with the ability to beat the competition on analytics. They provide a very rich set of in-database analytics and some add-on capabilities to improve the productivity of your data scientist team.
Their data load architecture, which they call scatter-gather, is a big differentiator. If your problem is that you cannot get data loaded and reports out in your nightly batch window then the combination of scatter-gather and the ability to run big report queries is unbeatable.
Greenplum also has a unique solution for near-real-time. They marry Gemfire, an in-memory object-oriented database, with scatter-gather to move small batches of inserted data to Greenplum with a very small time delta. I do not believe this solution supports inserts or deletes as they have to be applied directly to the Greenplum database… but it is a nice capability for a certain class of problems.
Where They Lose
Greenplum, like Teradata, can be beat when the problem to be solved is narrow. In these cases, when the database supports a single application with a small number of queries or when it supports a narrowly focussed data mart, they are vulnerable to Netezza, Vertica, or even Exadata. It is also sometimes the case that a poorly designed POC can narrow the scope enough that Greenplum loses.
Greenplum can also lose when a full EDW is required. The basic architecture of the RDBMS is capable of supporting an EDW… but some of the operational features required… RASR, workload, incremental backup, etc. are not mature. This may well be the intentional result of their focus away from these features at analytics.
In the Market
Despite the worries Greenplum should be included in every POC. They will push Teradata hard in performance and in price/performance.
As noted here… I do not understand their market strategy. It seems that they are competing with themselves by offering Hadoop for analytics… but this cannot be a bad thing for customers even if it is an odd position in the market. The analytics market they favor is tough… relatively small (compared to the DW space)… emerging… there are several capable competitors… and the market is haunted by the same problem that killed the data mining market in the mid-1990’s… there are just not enough skilled data scientists (see here).
My Guess at the Future
I cannot guess at the future of Greenplum… They are being moved into a new business unit that could be spun into a new company that has a charter to build software for the cloud (see here). This is odd in several dimensions. First, as I noted here, the shared nothing architecture Greenplum is built on is not a perfect fit for the cloud. There are ways to get around this (maybe the topic for a future post?) but it will require development in a fundamentally new direction. Further, the new division seems to be a software-only venture. This makes the future of the EMC Greenplum Data Computing Appliance uncertain. I suppose that there will be announcements soon to clarify these questions… but the architectural disconnects make it likely that there will be some arm-waving for a while.
If I were the Register I would have titled this: Raging Stuffed Elephant To Devour Two Warehouse Vendors… I love the Register… if you do not read it have a look…
This is a post is about the market implications of architecture…
Let us assume that Hadoop matures and finds a permanent place in the market. This is not certain with some folks expressing concern (here) and others boundless enthusiasm (here). So let’s assume… and consider where it might fit.
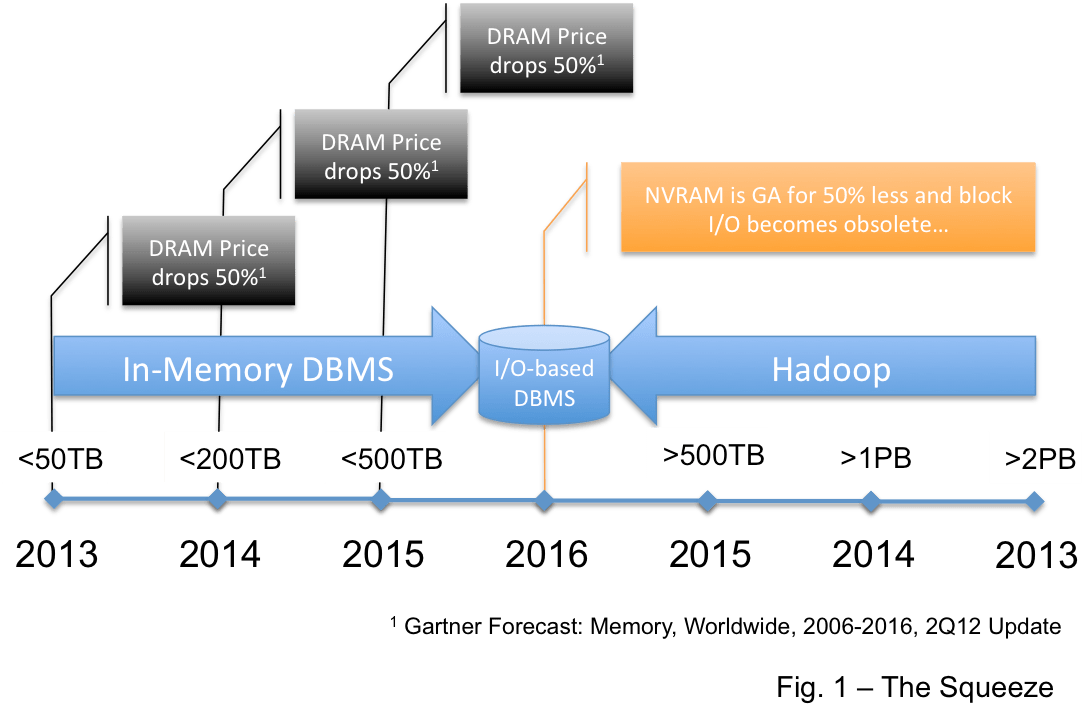
One place is in the data warehouse market… This view says Hadoop replaces the DBMS for data warehouses. But the very mature BI/DW market requires a high level of operational integrity and Hadoop is not there yet… it is advancing rapidly as an enterprise platform and I believe it will get there… but it will be 3-4 years. This is the thinking I provided here that leads me to draw the picture in Figure 1.
It is not that I believe that Hadoop will consume the data warehouse market but I believe that very large EDW’s… those over 1PB… and maybe over 500TB will be compelled by the economics of “free” to move big warehouses to Hadoop. So Hadoop will likely move down into the EDW space from the top.
Another option suggests that Big Data will be a platform unto itself. In this view Hadoop will sit beside the existing BI/DW platform and feed that platform the results of queries that derive structure from unstructured data… and/or that aggregate Big Data into consumable chunks. This is where Hadoop sits today.
In data warehouse terms this positions Hadoop as a very large independent analytic data mart. Figure 2 depicts this. Note that an analytics data mart, and a Hadoop cluster, require far less in the way of operational infrastructure… they share very similar technical requirements.
This leads me to the point of this post… if Hadoop becomes a very large analytic data mart then where will Greenplum and Netezza fit in 2-3 years? Both vendors are positioning themselves in the analytic space… Greenplum almost exclusively so. Both vendors offer integrated Hadoop products… Greenplum offers the Greenplum database and Hadoop in the same hardware cluster (see here for their latest announcement)… Netezza provides a Hadoop connector (here). But if you believe in Hadoop… as both vendors ardently do… where do their databases fit in the analytics space once Hadoop matures and fully supports SQL? In the next 3-4 years what will these RDBMSs offer in the big data analytics space that will be compelling enough to make the configuration in Figure 3 attractive?
I know that today Hadoop cannot do all that either Netezza or Greenplum can do. I understand that Netezza has two positions in the market… as an analytic appliance and as a data mart appliance… so it may survive in the mart space. But the overlap of technical requirements between Hadoop and an analytic data mart… combined with the enormous human investment in Hadoop R&D, both in the core and in the eco-system… make me wonder about where “Big Data” analytic relational databases will fit?
Note that this is not a criticism of the Greenplum RDBMS. Greenplum is a very fine product, one of the best EDW platforms around. I’ll have more to say about it when I provide my 2 Cents… But if Figure 2 describes the end state for analytics in 2-3 years then where is the place for the Figure 3 architecture? If Figure 3 is the end state then I do not see where the line will be drawn between the analytic workload that requires Greenplum and that that will run on Hadoop? I barely can see it now… and I cannot see it at all in the near future.
Both EMC Greenplum and IBM seem to strongly believe in Hadoop… they must see the overlap in functionality and feel the market momentum of Hadoop. They must see, better than most, that Hadoop wins this battle.
When I was at Greenplum… and now again at SAP… I ran into a strange logic from Teradata about query concurrency. They claimed that query concurrency was a good thing and an indicator of excellent workload management. Let’s look at a simple picture of how that works.
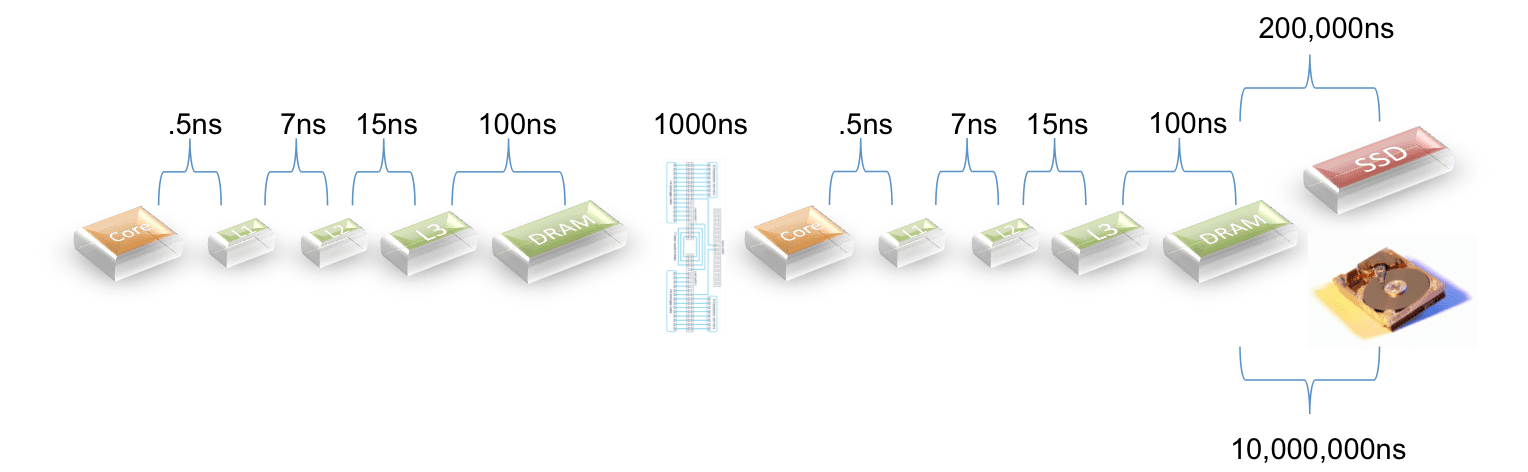
In Figure 1 we depict a single query on a Teradata cluster. Since each node is working in parallel the picture is representative no matter how many nodes are attached. In the picture each line represents the time it takes to read a block from disk. To make the picture simple we will show I/O taking only 1/10th of the clock time… in the real world it is slower.
Given this simplification we can see that a single query can only consume 10% of the CPU… and the rest of the time the CPU is idle… waiting for work. We also represented some I/O to spool files… as Teradata writes all intermediate results to disk and then reads them in the next step. But this picture is a little unfair to Greenplum and HANA as I do not represent spool I/O completely. For each qualifying row the data is read from the table on disk, written to spool, and then read from spool in the subsequent step. But this note is about concurrency… so I simplified the picture.
Figure 2 shows the same query running on Greenplum. Note that Greenplum uses a data flow architecture that pushes tuples from step to step in the execution plan without writing them to disk. As a result the query completes very quickly after the last tuple is scanned from the table.
Let me say again… this story is about CPU utilization, concurrency, and workload management… I’m not trying to say that there are not optimizations that might make Teradata outperform Greenplum… or optimizations that might make Greenplum even faster still… I just want you to see the impact on concurrency of the spool architecture versus the data flow architecture.
Note that on Greenplum the processors are 20% busy in the interval that the query runs. For complex queries with lots of steps the data flow architecture provides an even more significant advantage to Greenplum. If there are 20 steps in the execution plan then Teradata will do spool I/O, first writing then reading the intermediate results while Greenplum manages all of the results in-memory after the initial reads.
In Figure 3 we see the impact of having the data in-memory as with HANA or TimeTen. Again, I am ignoring the implications of HANA’s columnar orientation and so forth… but you can clearly see the implications by removing block I/O.
Now let’s look at the same pictures with 2 concurrent queries. Let’s assume no workload management… just first in, first out.
In Figure 4 we see Teradata with two concurrent queries. Teradata has both queries executing at the same time. The second query is using up the wasted space made available while the CPUs wait for Query 1’s I/O to complete. Teradata spools the intermediate results to disk; which reduces the impact on memory while they wait. This is very wasteful as described here and here (in short, the Five Minute Rule suggests that data that will be reused right away is more economically stored in memory)… but Teradata carries a legacy from the days when memory was dear.
But to be sure… Teradata has two queries running concurrently. And the CPU is now 20% busy.
Figure 5 shows the two-query picture for Greenplum. Like Teradata, they use the gaps to do work and get both queries running concurrently. Greenplum uses the CPU much more efficiently and does not write and read to spool in between every step.
In Figure 6 we see HANA with two queries. Since one query consumed all of the CPU the second query waits… then blasts through. There is no concurrency… but the work is completed in a fraction of the time required by Teradata.
If we continue to add queries using these simple models we would get to the point where there is no CPU available on any architecture. At this point workload management comes into play. If there is no CPU then all that can be done is to either manage queries in a queue… letting them wait for resources to start… or start them and let them wastefully thrash in and out… there is really no other architectural option.
So using this very simple depiction eventually all three systems find themselves in the same spot… no CPU to spare. But there is much more to the topic and I’ve hinted about these in previous posts.
Starting more queries than you can service is wasteful. Queries have to swap in and out of memory and/or in and out of spool (more I/O!) and/or in and out of the processor caches. It is best to control concurrency… not embrace it.
Running virtual instances of the database instead of lightweight threads adds significant communications overhead. Instances often become unbalanced as the data returned makes the shards uneven. Since queries end when the slowest instance finishes it’s work this can reduce query performance. Each time you preempt a running query you have to restore state and repopulate the processor’s cache… which slows the query by 12X-20X. … Columnar storage helps… but if the data is decompressed too soon then the help is sub-optimal… and so on… all of the tricks used by databases and described in these blogs count.
But what does not count is query concurrency. When Teradata plays this card against Greenplum or HANA they are not talking architecture… it is silliness. Query throughput is what matters. Anyone would take a system that processes 100,000 queries per hour over a system that processes 50,000 queries per hour but lets them all run concurrently.
I’ve been picking on Teradata lately as they have been marketing hard… a little too hard. Teradata is a fine system and they should be proud of their architecture and their place in the market. I am proud to have worked for them. I’ll lay off for a while.
Here is an attempt to build a Price/Performance model for several data warehouse databases.
Added on February 21, 2013: This attempt is very rough… very crude… and a little too ambitious. Please do not take it too literally. In the real world Greenplum and Teradata will match or exceed the price/performance of Exadata… and the fact that the model does not show this exposes the limitations of the approach… but hopefully it will get you thinking… – Rob
For price I used some $$/Terabyte numbers scattered around the internet. They are not perfect but they are close enough to make the model interesting. I used:
Of these numbers the one that may be the furthest off is the HANA number. This is odd since I work for SAP… but I just could not find a good number so I picked a big number to see how the model came out. Please, for any of these numbers provide a comment and I’ll adjust.
For each product I used the high performance product rather than the product with large capacity disks…
I used latency as a stand-in for performance. This is not perfect either… but it is not too bad. I’ll try again some other time and add data transfer time to the model. Note that I did not try to account for advantages and disadvantages that come from the software… so the latency associated with I/O to spool/work files is not counted… use of indexes and/or column store is not counted… compression is not counted. I’ll account for some of this when I add in transfer times.
I did try to account for cache hits when there is SSD cache in the configuration… but I did not give HANA credit for the work done to get most data from the processor caches instead of from DRAM.
For network latency I just assumed one round trip for each product…
For latencies I used the picture below:
The exception is that for products that use PCIe to access SSDs I cut the latency by 1/3 based on some input from a vendor. I could not find details on the latency for Teradata’s Bynet so I assumed that it is comparable with Infiniband and the newest 10GigE switches.
Here is what I came up with:
Database
Total Latency(ns)
Price/Performance
Delta
HANA
90
1,800
–
HANA (2 nodes)
1190
23,800
13x
Exadata X3
2,054,523
13,559,854
7533x
Teradata
4,121,190
27,199,854
15111x
Greenplum
10,001,190
30,003,570
16669x
I suppose that if a model seems to reflect reality then it is useful?
HANA has the lowest latency because it is in-memory. When there are two nodes a penalty is paid for crossing the network… this makes sense.
Exadata does well because the X3 product has SSD cache and I assumed an 80% hit ratio.
Teradata does a little worse because I assumed a lower hit ratio (they have less SSD per TB of data).
Greenplum does worse as they do all I/O against disks.
Note the penalty paid whenever you have to go to disk.
Let me say again… this model ignores lots of software features that would affect performance… but it is pretty interesting as a start…
There is a persistent myth, like a persistent cough, that claims that in-memory databases lose data when a hardware failure takes down a node because memory is volatile and non-persistent. This myth is marketing, not architecture.
Most RDBMS products: including Oracle, TimesTen, and HANA; have three layers where data exists: in-memory (think SGA for Oracle), in the log, and on disk. The normal process goes like this:
A write transaction arrives
The transaction is written to the log file and committed… this is a very quick process with 1 sequential I/O… quicker still if the log file is on a SSD device
The query updates the in-memory layer; and
After some time passes, saves the in-memory data to disk.
Recovery for these databases is easy to understand:
If a hardware failure occurs and #1 but before #2 the transaction has not been committed and is lost.
If a hardware failure occurs after #2 but before #3 the transaction is committed and the database is rebuilt when the node restarts from the log file.
If a hardware failure occurs after #3 but before #4 the same process occurs… the database is rebuilt when the node restarts from the log file.
If a hardware failure occurs after #4 the database is rebuilt from the disk copy.
“Unlike traditional distributed databases, SQLFire does not use write-ahead logging for transaction recovery in case the commit fails during replication or redundant updates to one or more members. The most likely failure scenario is one where the member is unhealthy and gets forced out of the distributed system, guaranteeing the consistency of the data. When the failed member comes back online, it automatically recovers the replicated/redundant data set and establishes coherency with the other members. If all copies of some data go down before the commit is issued, then this condition is detected using the group membership system, and the transaction is rolled back automatically on all members.”
Redundant in-memory data optimizes transaction throughput but requires twice the memory. There are options to persist data to disk… but these options provide an approach that is significantly slower than the write-ahead logging used by TimesTen and HANA (and Oracle and Postgres, and …).
The bottom line: IMDBs are designed in the same manner as other, disk-based, DBMSs. They guarantee that comitted data is safe… everytime.
P.S.
See here for how these DBMSs compare when a BI/analytic workload is applied.
As you may have noticed I’m looking at in-memory databases (IMDB) these days… Here are some quick architectural observations on VMWare‘s SQLFire, Oracle’s Exalytics and TimesTen offerings, and SAP HANA.
It is worth noting up front that I am looking to see how these products might be used to build a generalized data mart or a data warehouse… In other words I am not looking to compare them for special case applications. This is important because each of these products has some extremely cool features that allow them to be applied to application-specific purposes with a narrow scope of data and queries… maybe in a later blog I can try to look at some narrow use-cases.
Further, to make this quick blog tractable I am going to assume that the mart/dw problem to be solved requires more data than can fit on one server node… and I am going to ignore features that let queries access data that resides on disk… in-memory or bust.
Finally I will assume that the SQL dialect supported is sufficient and not drill into details there. I will look at architecture not SQL features…
Simply put I am going to look at a three characteristics:
Will the architecture support ad hoc queries?
Does the architecture support scale-out?
Can we say anything with regards to price/performance expectations?
Exalytics is a smart-aggregate store that sits over an Oracle database to offload aggregate query workload (see my previous post here or the Rittman Mead post here which declares: “Oracle Exalytics uses a specially enhanced version of Oracle TimesTen, Oracle’s in-memory database, to cache commonly used aggregates used in dashboards, analyses and other BI objects.” Exalytics does not support a scale-out shared-nothing architecture but it can scale up by adding nodes with new aggregate data. Queries access data within the aggregate structure and it is not possible to join to data off the Exalytics node… so ad hoc is out. Within these limits, which preclude Exalytics from being considered as a general platform for a mart or warehouse, Exalytics provides dictionary-based compression which should provide around 5X compression to reduce the amount of memory required and reduce the amount of hardware required.
TimesTen can do more. It is a general RDBMS. But it was designed for OLTP. I assume that the reason that Oracle has not rolled it out as a general-purpose data mart or data warehouse has to do with constraints that grow from those OLTP architectural roots. For example, BI queries run longer and require more data than a OLTP query… and even with data in-memory temporary storage is required for each query… and memory utilization is a product of the amount of data required and the amount of time the data has to inhabit memory… so BI queries put far more pressure on an in-memory DBMS. There are techniques to mitigate this… but you have to build the techniques in from the ground up.
I imagine that this is why TimesTen works for Exalytics, though. A OLAP query against a pre-aggregated cube does not graze an entire mart or warehouse. It is contained and “small data” (for my wacky take re: Exalytics and Exadata see here).
TimeTen is not sharded… so scalability is an issue. Oracle gets around this nicely by allowing you to partition data across instances and have the application route queries to the appropriate server. But this approach will not support joins across partitions so it severely limits scalability in a general-purpose mart or warehouse.
SQLFire is a very interesting new product built on top of Gemfire… and therefore mature from the start. SQLFire is more scalable than TimesTen/Exalytics. It supports sharded data in a cluster of servers. But SQLFire has the limitation that it cannot join data across shards (they call them partitions… see here) so it will be hard to support ad hoc queries… They provide the ability to replicate tables to support any sort of joins. If, for example, you replicate small dimension tables to coexist with sharded fact tables all joins are supported. This solution is problematic if you have multiple fact tables which must be joined… and replication of data uses more memory… but SQLFire has the foundation in place to become BI-capable over time.
Performance in an in-memory database comes first and foremost from eliminating disk I/O. All three IMDB product provide this capability. Then performance comes from the efficient use of compression. TimeTen incorporates Oracles dictionary-based “columnar” compression (I so hate this term… it is designed to make people think that Oracle products are sort-of columnar… but so far they are not). Then performance comes from columnar projection… the ability to avoid touching all data in a row to process a query. Neither TimesTen nor SQLFire are columnar databases. Then performance comes from parallel execution. Neither TimesTen nor SQLFire can involve all cores on a single query to my knowledge.
Price comes from compression as well. The more highly compressed the data is the less memory required to store it. Further, if data can be used without decompressing it, then less working memory is required. As noted, TimesTen has a compression capability. SQLFire does not appear to compress data. Neither can use compressed data. Note that 2X compression cuts the amout of memory/hardware required in half or more… 4X cuts it to a quarter… and so on. So this is significant.
Now for some transparency… I started the research for this blog, and composed a 1st draft, last Spring while I was at EMC Greenplum. I am now at SAP working with HANA. So… I will not go into HANA at great length… but I will point out that: HANA fully supports a shared-nothing architetcture… so it is fully scalable; HANA is fully parallel and able to use all cores for each query; HANA fully supports columnar tables so it provides deep compression and the ability to use the compressed data in execution. This is not remarkable as HANA was designed from the bottom up to support both BI and OLTP workloads while TimesTen and SQLFire started from a purely OLTP architectural foundation.
Several months ago I was invited to a dinner attached to a data science summit… with the price being that I had to deliver a 5 minute talk… I had to sing for my dinner. The result was this thinking on real-time analytics and the Toyota Prius.
Real-time analytics implies two things:
Changes in the data are evaluated continuously; and
The results of the analysis are used or displayed continuously.
In a Toyota Prius we can see two examples of real-time analytics.
The first is in the anti-lock braking system. There data reflecting the pressure on the brake pedal and on rotation of each wheel is sent to a computer that analyzes the results and adjusts the brake pressure on each wheel so that all four wheels turn at the same rate and the car stops in a straight line.
Note that the analytics are real-time and the results are used immediately without human intervention. This is important. It makes little sense to spend the money to capture and analyze data in real-time if the results are not actionable in near-real-time.
Think for a moment about the BI systems built over the last 20 years. First we captured and analyzed monthly data… and acted on that data within a 30-day window. Then we increased the granularity of the data to weekly and slightly adjusted the reports to reflect the finer granularity… and acted on the data within 7 days. Then we adjusted the data to daily and acted on the results each day. Then we adjusted the data to hourly and reacted even more quickly. These changes often did not fundamentally change the business processes driven by the data… they just made the processes more sensitive to the fine-grained information.
But if the data-driven business process takes ten minutes to complete… for example it takes ten minutes for staff to pick inventory, package the results, and load a delivery truck; could there be a return on the investment expense of developing a continuous, real-time analytic? I think not. There may, however, be ROI associated with a new robotic pick, package, and load process…
There is another possibility… If sometimes the pick, package, and load takes ten minutes and sometimes it takes fifteen minutes then the best solution is to perform the analytics on the current state on-demand… when there are resources to support the process. This maximizes the use of the resources without changing the business process.
The point here is that real-time requires a re-think… or at least a deep-think. The business process may have to change significantly to support real-time analytics.
The second real-time system in the Prius illustrates the problem. On the dashboard the Prius displays, in real-time, the state of the hybrid gas-electric system. It shows whether the battery is charging or discharging… it shows whether the car is being driven using the electric or the internal-combustion engine. It is one of the most beautiful dashboard displays you have ever seen… and executives everywhere must look at it and wonder why they cannot get such a beautiful display of the state of their business… after-all… BI dashboards are “the thing”.
But the Prius display is useless. There is no action you would take while driving based on this real-time display.From a decision-making view it represents useless and expensive flash (that helps to sell the Prius…).
So… approach real-time analytics with a deep-think. Look for opportunities like the anti-lock braking system where real-time analytics can be embedded into automatic business processes. Avoid flashy dashboards that do not present actionable data.
In-memory databases (IMDB) such as SAP HANA, Oracle TimesTen, and VMWare SQLFire promise to enable real-time analytics… and this promise is real… the opportunities can and will revolutionize the enterprise over time… but a revolution is not the same old BI at a finer granularity… it is much more significant than that. Heads will roll.
In the previous blogs on this topic (Part 1, Part 2, Part 3) I suggested that:
Shared-nothing is required for an EDW,
An EDW is not usually under-utilized,
There are difficulties in re-distributing sharded, shared-nothing data to provide elasticity, and
A SAN cannot provide the same IO bandwidth per server as JBOD… nor hit the same price/performance targets.
Note that these issues are tied together. We might be able to spread the EDW workload over so many shards and so many SANs that the amount of I/O bandwidth per GB of EDW data is equal to or greater than that provided on a DW Appliance. This introduces other problems as there are typically overhead issues with a great many nodes. But it could work.
But what if we changed the architecture so that I/O was not the bottleneck? What if we built a cloud-based shared-nothing in-memory database (IMDB)? Now the data could live on SAN as it would only be read at start-up and written at shut-down… so the issues with the disk subsystem disappear… and issues around sharing the SAN disappear. Further, elasticity becomes feasible. With an IMDB we can add and delete nodes and re-distribute data without disk I/O… in fact it is likely that a column store IMDB could move column-compressed data without re-building rows. IMDB changes the game by removing the expense associated with disk I/O.
There is evidence emerging that IMDB technology is going to change the playing field (see here).
Right now there are only a few IMDB products ready in the market:
TimeTen: which is not shared-nothing scalable, nor columnar, but could be the platform for a very small, 400GB or less (see here), cloud-based EDW;
SQLFire: which is semi-shared-nothing scalable (no joins across shards), not columnar, but could be the platform for a larger, maybe 5TB, specialized EDW;
ParAccel: which is shared-nothing scalable, columnar, but not fully an IMDB… but could be (see C. Monash here); or
SAP HANA: which is shared-nothing, IMDB, columnar and scalable to 100TB (see here).
So it is early… but soon enough we should see real EDWs in the cloud and likely on Amazon EC2, based on in-memory database technologies.