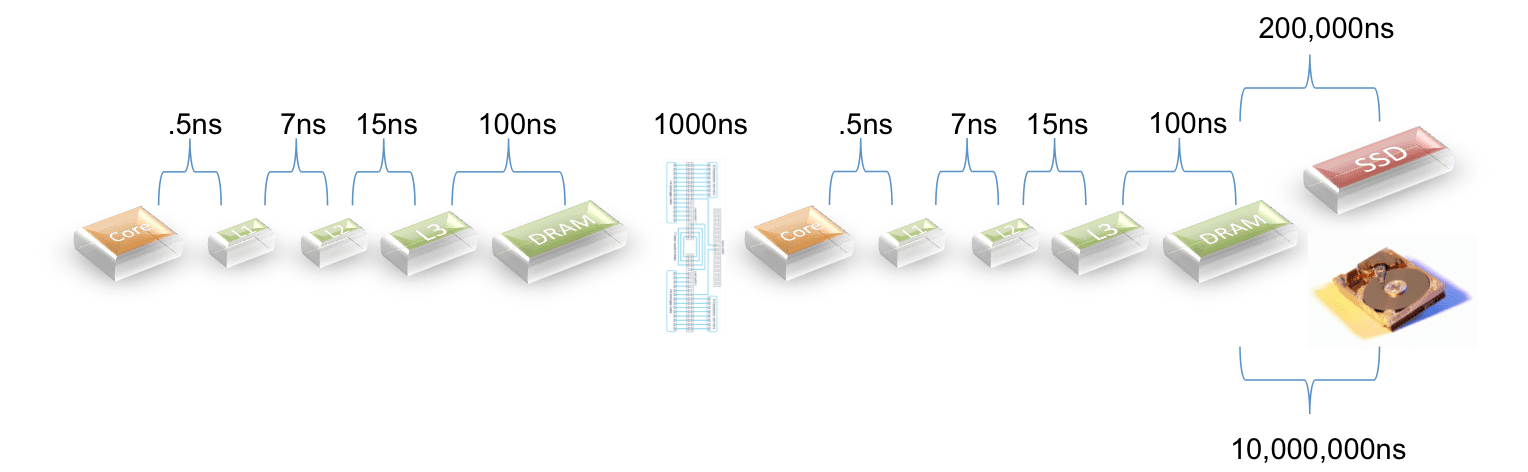
When I was at Greenplum… and now again at SAP… I ran into a strange logic from Teradata about query concurrency. They claimed that query concurrency was a good thing and an indicator of excellent workload management. Let’s look at a simple picture of how that works.
In Figure 1 we depict a single query on a Teradata cluster. Since each node is working in parallel the picture is representative no matter how many nodes are attached. In the picture each line represents the time it takes to read a block from disk. To make the picture simple we will show I/O taking only 1/10th of the clock time… in the real world it is slower.

Given this simplification we can see that a single query can only consume 10% of the CPU… and the rest of the time the CPU is idle… waiting for work. We also represented some I/O to spool files… as Teradata writes all intermediate results to disk and then reads them in the next step. But this picture is a little unfair to Greenplum and HANA as I do not represent spool I/O completely. For each qualifying row the data is read from the table on disk, written to spool, and then read from spool in the subsequent step. But this note is about concurrency… so I simplified the picture.
Figure 2 shows the same query running on Greenplum. Note that Greenplum uses a data flow architecture that pushes tuples from step to step in the execution plan without writing them to disk. As a result the query completes very quickly after the last tuple is scanned from the table.

Let me say again… this story is about CPU utilization, concurrency, and workload management… I’m not trying to say that there are not optimizations that might make Teradata outperform Greenplum… or optimizations that might make Greenplum even faster still… I just want you to see the impact on concurrency of the spool architecture versus the data flow architecture.
Note that on Greenplum the processors are 20% busy in the interval that the query runs. For complex queries with lots of steps the data flow architecture provides an even more significant advantage to Greenplum. If there are 20 steps in the execution plan then Teradata will do spool I/O, first writing then reading the intermediate results while Greenplum manages all of the results in-memory after the initial reads.
In Figure 3 we see the impact of having the data in-memory as with HANA or TimeTen. Again, I am ignoring the implications of HANA’s columnar orientation and so forth… but you can clearly see the implications by removing block I/O. 
Now let’s look at the same pictures with 2 concurrent queries. Let’s assume no workload management… just first in, first out.
In Figure 4 we see Teradata with two concurrent queries. Teradata has both queries executing at the same time. The second query is using up the wasted space made available while the CPUs wait for Query 1’s I/O to complete. Teradata spools the intermediate results to disk; which reduces the impact on memory while they wait. This is very wasteful as described here and here (in short, the Five Minute Rule suggests that data that will be reused right away is more economically stored in memory)… but Teradata carries a legacy from the days when memory was dear.

But to be sure… Teradata has two queries running concurrently. And the CPU is now 20% busy.
Figure 5 shows the two-query picture for Greenplum. Like Teradata, they use the gaps to do work and get both queries running concurrently. Greenplum uses the CPU much more efficiently and does not write and read to spool in between every step.

In Figure 6 we see HANA with two queries. Since one query consumed all of the CPU the second query waits… then blasts through. There is no concurrency… but the work is completed in a fraction of the time required by Teradata.

If we continue to add queries using these simple models we would get to the point where there is no CPU available on any architecture. At this point workload management comes into play. If there is no CPU then all that can be done is to either manage queries in a queue… letting them wait for resources to start… or start them and let them wastefully thrash in and out… there is really no other architectural option.
So using this very simple depiction eventually all three systems find themselves in the same spot… no CPU to spare. But there is much more to the topic and I’ve hinted about these in previous posts.
Starting more queries than you can service is wasteful. Queries have to swap in and out of memory and/or in and out of spool (more I/O!) and/or in and out of the processor caches. It is best to control concurrency… not embrace it.
Running virtual instances of the database instead of lightweight threads adds significant communications overhead. Instances often become unbalanced as the data returned makes the shards uneven. Since queries end when the slowest instance finishes it’s work this can reduce query performance. Each time you preempt a running query you have to restore state and repopulate the processor’s cache… which slows the query by 12X-20X. … Columnar storage helps… but if the data is decompressed too soon then the help is sub-optimal… and so on… all of the tricks used by databases and described in these blogs count.
But what does not count is query concurrency. When Teradata plays this card against Greenplum or HANA they are not talking architecture… it is silliness. Query throughput is what matters. Anyone would take a system that processes 100,000 queries per hour over a system that processes 50,000 queries per hour but lets them all run concurrently.
I’ve been picking on Teradata lately as they have been marketing hard… a little too hard. Teradata is a fine system and they should be proud of their architecture and their place in the market. I am proud to have worked for them. I’ll lay off for a while.