Cloudera and Teradata have jointly published a nice paper here that presents an interesting perspective of how Hadoop and an EDW play together. Simply put, Hadoop becomes the staging area for “raw data streams” while the EDW stores data from “operational systems”. Hadoop then analyzes the raw data and shares the results with the EDW. Two early examples provided suggest:
- Click stream data is analyzed to identify customer preferences that are then shared with the EDW. Note that the amount of data sent from Hadoop to the EDW would be fairly small in this case.
- Detailed data is stored on Hadoop to build analytic models. The models are then transferred to the EDW to score sales activity data. Note that in this scenario the scored activity detail has to live in Hadoop to perform modeling… but it is unclear why it has to live in the EDW as well. I presume that scoring takes place on the EDW instead of in Hadoop for performance reasons… but maybe the data, the modeling, and the scoring should just take place in Hadoop?
The paper then positions Hadoop as an active archive. I like this idea very much. Hadoop can store archived data that is only accessed once a month or once a quarter or less often… and that data can be processed directly by Hadoop programs or shared with the EDW data using facilities such as Teradata’s SQL-H, or Greenplum‘s External Hadoop tables (not by HAWQ, though… see here), or by other federation engines connected to HANA, SQL Server, Oracle, etc.
But think about the implications on how much data has to stay in your EDW if you archive everything older than 90, or even 180, days to Hadoop. The EDW shrinks significantly and the TCO advantage to your Enterprise will be significant. This is very cool.
There is one item in the paper I disagree with, though… and another statement that I think has a very short shelf-life.
The paper suggests that indexes, materialized views, aggregate join indexes, and other tweaks are what differentiates an EDW. I believe that reliance on these structures make for a fragile EDW where only some queries can run fast. I like Teradata better when it just robustly scans fast and none of these redundant-data tuning artifacts are required (more here and here). Teradata was the original scan-fast DBMS… it is more than capable.
The paper also suggests that an EDW maintains value by including a sophisticated cost-based optimizer that uses data demographic statistics to identify an optimal query execution plan. I agree that Hadoop lacks this now… but there are several projects like Cloudera Impala that will eliminate this gap in the near term.
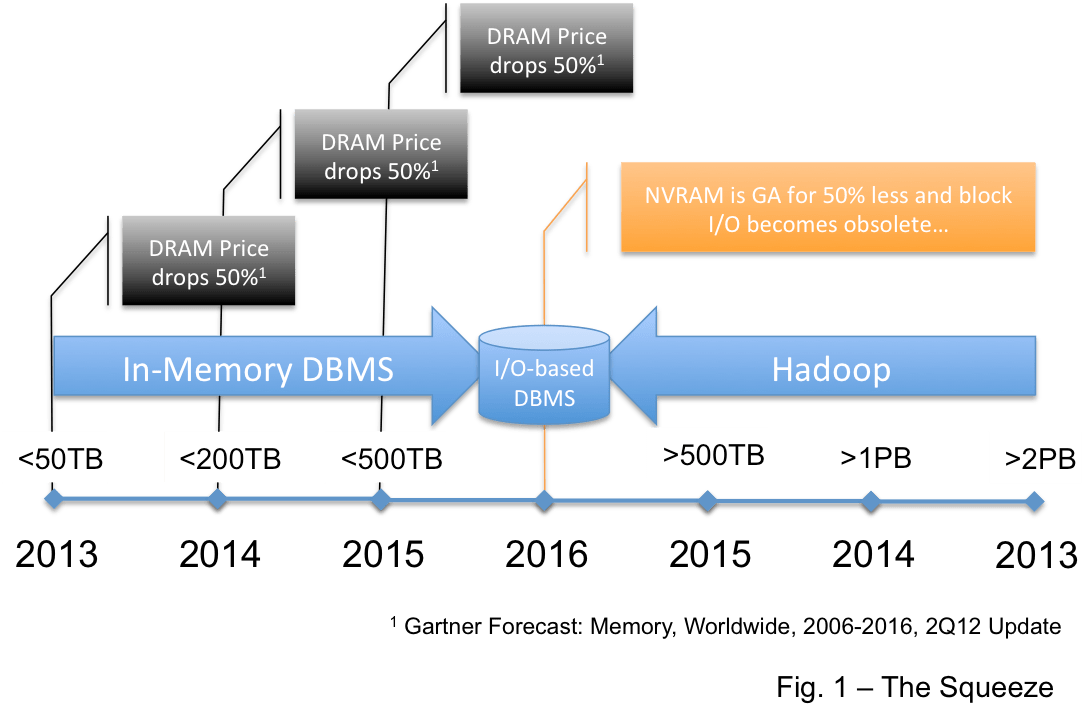
I believe that if you read between the lines you will see more evidence to support my belief (here) that Hadoop will squeeze the EDW vendors hard… and that the size of a squeezed EDW will then fit in an in-memory database.