As preface to this you might check out the definition I suggested for Big Data last week here… – Rob
I left Greenplum in large part because they made their mark in… and then abandoned… the data warehouse market for a series of big hype plays: first analytics and data science; then analytics, data science, and Hadoop; then they went “all-in”, their words, on Big Data and Hadoop… and now they are part of Pivotal and in a place that no-one can clearly define… sort of PaaS where Greenplum on HDFS is a platform.
It is not that I am a Luddite… I pretend each time I write this blog that I am in tune with the current and future state of the database markets… that I look ahead now and then. I just thought that it was unlikely for Greenplum to be profitable by abandoning the market that made them. At the time I suggested to them an approach that was founded in data warehousing but would let them lead in the hyped plays… and be there in front when, and if, those markets matured.
Now, if we were to define markets in an unambiguous manner:
- a data warehouse database is primarily accessed through one or more BI tools;
- an analytic database is primarily accessed through a statistical tool; and
- Hadoop requires Hadoop;
then I suspect that the vast majority of Greenplum revenues still, 3-4 years after the move away from data warehousing, come from the DW market. It is truly a shame that this is not the focus of their engineering team and their marketeers.
Gartner has called it pretty accurately in their 2013 Hype Cycle for Emerging Technologies here. Check out where Big Data is on the curve and how long until it reaches the mainstream. Worse, here is a drill-down showing the cycle for just Big Data. Look at where Data Science sits and when they expect it to plateau. Look at where SQL for Hadoop is in the cycle.
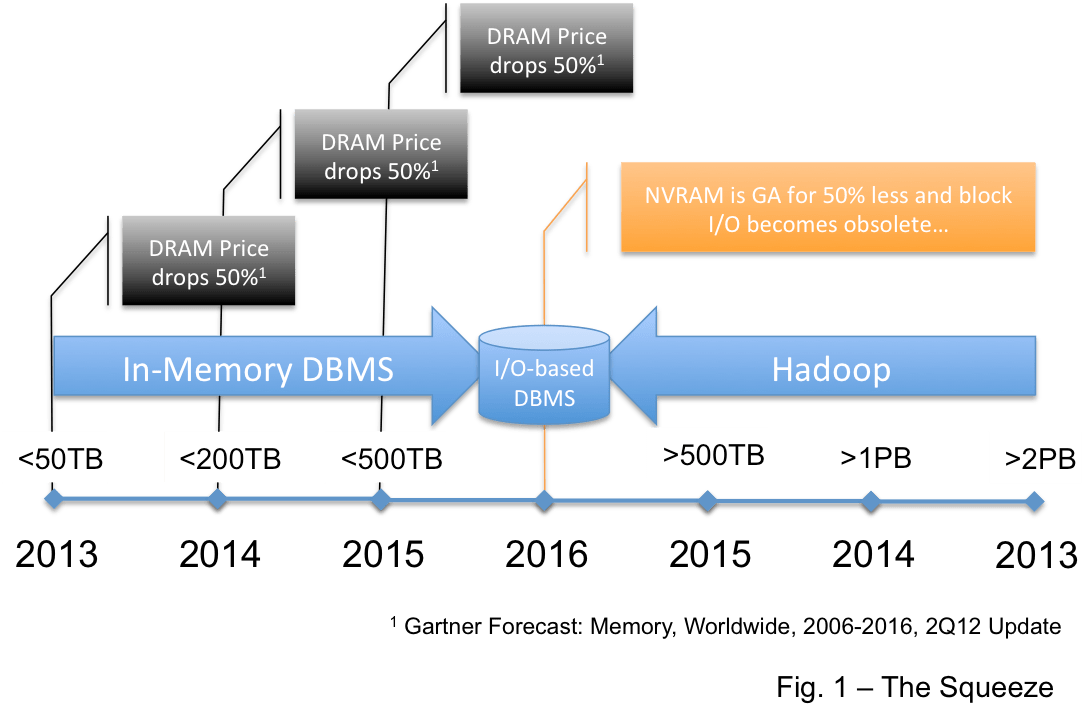
Big Data is real and upcoming… but there is no concise definition of Big Data… no definition that does not overlap technologies that have been around since before the use of the term. There is no definition that describes a technology that the Fortune 1000 will take mainstream in the next 2-3 years. Further, as I have suggested here and here, open source products like Hadoop will annihilate the commercial market for big analytic databases and squeeze hard the big EDW DBMS players. It is just not a commercially interesting space… and it may not become commercially interesting if open source dominates (unless you are a services company).
Vendors need to be looking hard at Big Data now if they want to play in 2-3 years. They need to be building Big Data integration into their products and they need to be building Big Data apps that take the value straight into the business.
Users need to be looking carefully for opportunities to use Hadoop to reduce costs… and, in highly competitive markets which naturally generate lots of machine-to-machine data, they need to look for opportunities to get ahead of the competition.
But both groups need to understand that they are on the wrong side of the chasm (see here for reference to Crossing the Chasm)… they have to be Early Adopters with a culture that supports an early adopter business model.
We all need to avoid the mistake described in the introduction. We need to find commercially viable spots in an emerging technology play where we can deliver profits and ROI to our organizations. It is not that hard really to see hype coming if you are paying attention… not that hard to be a minor visionary. It is a lot harder to turn hype into profits…