Now for HANA plus Hadoop… to continue this thread on RDBMS-Hadoop integration (Part 1, Part 2,Part 3,Part 4, Part 5) I have suggested that we could evaluate integration architecture using three criteria:
How parallel are the pipes to move data between the RDBMS and the parallel file system;
Is there intelligence to push down predicates; and
Is there more intelligence to push down joins and other relational operators?
As a preface I need to include a note/apology. As you will see HANA may well have the best RDBMS-Hadoop integration in the market. I try hard not to blow foam about HANA in this blog… and I hope that the objective criteria I have devised to evaluate all of the products will keep this post credible… but please look at this post harder than most and push back if you think that I overstep.
First… surprisingly, HANA’s first release has only a single pipe to the Hadoop side. This is worrisome but easily fixed. It will negatively impact performance when large tables/files have to be moved up for processing.
But HANA includes Hadoop as a full partner in a federated data architecture using the Smart Data Access (SDA) engine inside the HANA address space. As a result, HANA not only pushes predicates but it uses cost-based optimization to determine what to push down and what to pull up. HANA interrogates the Hadoop system to gather statistics and uses the HANA optimizer to develop smart execution plans with awareness of both the speed of in-memory and the limited memory resources. When data in HANA is joined with data in Hadoop SDA effectively uses semi-joins to minimize the data pulled up.
Finally, HANA can develop execution plans that executes joins in Hadoop. This includes both joins between two Hadoop tables and joins where small in-memory tables are pushed down to execute the joins in Hadoop. The current limitation is that Hadoop files must be defined as Hive tables.
Here is the HANA execution plan for TPC-H query 19. HANA has pushed down all of the steps behind the Remote Row Scan step… so in this case the entire query including a nested loop join was pushed down. In other queries HANA will push only parts of the plan to Hadoop.
So HANA possesses a very sophisticated integration with Hadoop… with capabilities that minimize the amount of data moved based on the cost of the movement. This is where all products need to go. But without parallel pipes this sophisticated capability provides only a moderate advantage (see Part 5),
Note that this is not the ultimate in integration… there is another level… but I’ll leave some ideas for extending integration even further for my final post in the series.
Continuing this thread on RDBMS-Hadoop integration (Part 1, Part 2,Part 3,Part 4) I have suggested that we could evaluate integration architecture using three criteria:
How parallel are the pipes to move data between the RDBMS and the parallel file system;
Is there intelligence to push down predicates; and
Is there more intelligence to push down joins and other relational operators?
I want to be sure that I’ve conveyed the concepts behind these criteria properly… I may have rushed it in the early parts of this series.
Let’s imagine a query that joins a 2,000,000 row table with a 1000 row dimension table where both live in HDFS.
If all of the data has to be moved from HDFS to the RDBMS then 2,001,000 rows must be read and moved in order to apply a predicate or any other processing.. For fun lets say that the cost of moving this data is 2001K.
If there are 10 parallel pipes then the data movement is completed in one tenth the time… so the cost is 200K.
If a predicate is included that selects only 5% of the data from the big table, and the predicate is pushed down the cost is reduced to 101K. Add in parallel pipes and the cost is 10K
Imagine a query where there is a join between the two tables with predicates on one side and predicate push down… then you have to pay 101K to pull the projected data up and do the join in the RDBMS. If there is a join predicate that reduces the final answer set by another 95% then after the join you return 6K rows. Since everybody returns the same 6K rows as an answer we won’t add that in.
But if you can push the join down as well as the predicates then only 6K rows are moved up… so you can see how 2001K shrinks to 6K through the effective push down of processing.
Further, you can build arbitrarily complex queries and model them pretty well knowing that most of the cost is in data movement.
So think about how Teradata processes these two tables in Hadoop when you use the specialized SQL constructs and then again if you build the query from a BI tool. And stay tuned as I’ll show you how HANA processes the data next…. and then talk about several others.
In this thread on RDBMS-Hadoop integration (Part 1, Part 2,Part 3) I have suggested that we could evaluate integration architecture using three criteria:
How parallel are the pipes to move data between the RDBMS and the parallel file system;
Is there intelligence to push down predicates; and
Is there more intelligence to push down joins and other relational operators?
Let’s consider the Teradata SQL-H implementation using these criteria.
First, Teradata has effective parallel pipes to move data from HDFS to the Teradata database with one pipe per node. There does not seem to be any inter-node IO parallelism. This is a solid feature.
There is a limited ability to push down predicates… SQL-H does allow data to be partitioned on the HDFS side and it will perform partition elimination if the query explicitly calls out a predicate within a partionfilter() keyword. In addition there is an ability to project out columns using a columns() keyword to explicitly specify the columns to be returned. These features are klunky but effective. You would expect partitions to be eliminated when the partitioning column is referenced with a predicate in the query like any other query… and you would expect columns to be projected out if they are not referenced. Normal SQL predicates are applied after the data is moved over the network but before every record is written into the Teradata database.
Finally SQL-H provides no advanced capabilities to push down join operators or other functions.
The bottom line: SQL-H is a sort of klunky implementation, requiring non-ANSI-standard and non-Teradata standard SQL syntax. Predicate push down is limited but better than nothing. As you will see when we review other products, SQL-H is a basic offering. The lack of full predicate push-down and advanced features will negatively and severely impact performance when accessing large volumes of data, Big Data, and the special SQL syntax will limit the ability to access HDFS data from 3rd party tools. This performance penalty will force customers to pre-join and pre-aggregate data in Hadoop rather than access it naturally.
In the thread I’m now working on (Part 1, Part 2) I’ve talked about Exadata and a criteria for evaluating split architectures. It is worth quickly talking about homogeneous systems with no split like Teradata or Greenplum or HANA… systems with no separate query-capable top end.
Every parallel shared-nothing DBMS has big pipes to move data between nodes… and they have all of the advanced intelligence to reduce the amount of data moved both between nodes within a query.
So if we compare Exadata to a split system with an RDBMS and Hadoop it fairs very well. But if we compare Exadata to Teradata or Greenplum or HANA… then the bottlenecks in Exadata look more severe. Exadata may tie, or occasionally win, in a POC against these homogenous competitors when the queries fit their architectural sweet spot. But if any queries are included that expose the bottlenecks or the limitations in query push-down… Exadata’s weak split architecture shows.
In my blog yesterday (Part 1) I suggested that we could evaluate RDBMS-Hadoop integration architecture using three criteria:
How parallel are the pipes to move data between the RDBMS and the parallel file system;
Is there intelligence to push down predicates; and
Is there more intelligence to push down joins and other relational operators?
But Exadata is a split RDBMS with a parallel file system backing it… how does it measure up by these criteria?
There are effective parallel pipes between the Oracle RAC RDBMS and the Exadata Storage Subsystem… so Exadata passes the first test. Further, Exadata is smart about pushing scan and projection both down to the Storage layer.
Unfortunately there is a fairly severe imbalance between the number of nodes on the RAC side and the number of nodes on the Storage side and this creates a bottleneck. We cannot give Exadata full marks here… but as far as parallel pipes goes it stacks up pretty well.
The ability to push down predicates goes a long way towards solving this as the predicate push-down reduces the amount of data that has to move over the bottleneck. But in every data warehouse there will be queries that return lots of rows from the early execution steps… and Exadata cannot join data in the Storage Subsystem so it tries to pull data up sparingly and push down semi-joins whenever possible… it just cannot be done in every case (Note: in Exadata POCs Oracle will try to ensure that no queries are included that pull lots of data up to the RAC layer… and competitors will try to include queries that expose this weakness…).
So… Oracle also includes some intelligence to push some data down to reduce data movement. There is no way to choose to move data from the RAC layer to the Storage Subsystem and execute the query there… the Storage Subsystem can only scan and project… so again we cannot give Exadata full marks… but it is pretty smart as you will see when we start looking at alternative implementations.
Finally, Exadata cannot effectively split a single query plan across both layers… so no marks at all here.
So Exadata is pretty good… but it has weak spots that will be severe for an important set of DW queries in any implementation.
The next few blogs will try to evaluate the different approaches to integrating Hadoop and a standard RDBMS… so the first thing I’ll try in this post is to suggest a criteria based on some architectural choices for making the evaluation. Further, I’ll inject a little surprise and make the point by using the criteria to say something about a product that is not an integration of an RDBMS and Hadoop.
For the purposes of this let me clear that by “Hadoop” I mean at least HDFS plus MapReduce… so I will discuss integrating a parallel RDBMS with data stored in HDFS: a massively parallel file system with a programming capability included. By “integration” I mean that queries using the full set of SQL supported by the RDBMS must be available for processing queries that refer to data across the Hadoop-RDBMS divide.
Since we’ve assumed that all SQL functionality is supported the architectural issue left to solve is performance and this issue revolves on one topic: how do we minimize the cost of moving data between the two partners for a given query?
Now to get on with it…
The easiest, but not all that easy, problem involves using parallelism to move data from one system to the other… so the first criteria we will evaluate for each product will consider how parallel is their movement of data.
The next criteria involves intelligence in the RDBMS to push down some execution operators to the data layer. Of course the RDBMS must scan remote data… so in this part of the evaluation we will grade each product’s ability to push processing down to apply predicates and project the minimal amount of data up to the RDBMS.
Finally, a most intelligent product would push more than just predicates down… it would push down joins and aggregation… and the decisions around splitting processing would be fully optimized. A most intelligent product would fully federate the HDFS data into the RDBMS.
So there you have it… I will start evaluating RDBMS-Hadoop architecture by three criteria:
how parallel is the data movement between the RDBMS and Hadoop;
is there intelligence to minimize data movement by pushing the least data and the associated query plan to one system or another… this requires parallel pipes in both directions; and
is there intelligence to build an optimal query plan that splits steps across both systems to completely minimize the movement of data and/or optimize the compute.
And a final word on the relative strength of each criteria:
If we imagine a 10-node Hadoop cluster talking to a 10-node RDBMS with 10 parallel pipes and compared it to the same setup with only 1 pipe (not parallel) then we might suggest that the parallel pipes provide a 10X performance increase.
If we imagine intelligence that moved 100K rows rather than 10M then we might suggest that intelligent push down might provide a 100X performance increase…
If we had even more intelligence and further optimized processing then another 10X-100X might be possible.
So all three criteria are not equal… intelligent query planning trumps wide pipes…
Now for the surprise… in the next blog we’ll look at how Exadata’s architecture maps to these criteria… since it is a two-tiered architecture with an RDBMS tied to a parallel file system…
“That’s not a knife… THAT’S A KNIFE” – C. Dundee (Photo credit: Wikipedia)
Michael Stonbreaker has suggested several times… and again in this interview… that databases will become more specialized and that “one size will fit none”. I’m sure that his argument is more nuanced than the sound bites in the interview, but in this post I’ll suggest a line of thinking that may lead to a different conclusion.
First, let’s agree that the word “fit” means the best price for the performance required to meet your company’s service level requirements.
Then let’s agree with the basic premise behind Dr. Stonebreaker’s argument… we agree that in any single-purpose application a specialized single-purpose DBMS can be developed that will out perform a generalized DBMS. This means that one-half of the fit, performance, is likely.
We would also agree that between the growth of open source databases and the general growth in the database space that it is likely that someone can and will develop specialized databases and bring them to market in cases where there is enough market to make it worthwhile. But it is important to note that specialization will be not become infinitely narrow… there has to be enough market for the special case to generate an attractive product.
So where is the disagreement: I do not believe that data is ever used in a single specialized business context. Not ever.
Let’s imagine that we have a business requirement for an extremely high volume OLTP application… and let us assume that the performance and/or scalability requirements are beyond what any general DBMS can provide and that the business ROI is significant… in other words, let us imagine that we are Google or Facebook. In this case we have no choice but to select or to develop an extreme, specialized, DBMS to solve the problem and extract the return.
But in this case, once the OLTP transactions are recorded… what do we do with the data? We need to use the data elsewhere in the business as the basis for deep analytics or for basic business intelligence… so we have to replicate the data to a second database. Since the second DBMS is also sort of specialized… it does not have to support OLTP… we select a second specialized, data warehousish product.
And then come new requirements for doing light queries in near real time to support operational analytics… so we build some sort of operational data store. Again we can select a product with a narrow technical sweet spot… but we have to replicate the data a third time.
In other words… given my premise… that data is never used in a single specialized context… specialized databases force replication… and replication allows for further specialization.
But what if the requirements are not so extreme? Then we might use a single conventional RDBMS for the EDW and for the ODS problems. If a more generalized DBMS product exists that could handle both the operational reporting and the analytic reporting requirements in a single image of the data then we could eliminate one replica and one DBMS. In other words, if the problem is not so extreme then a generalized solution might provide a solution in a single instance of the data avoiding replication.
Now the issue becomes: is the cost of a specialized system plus replication plus a second specialized system plus the cost of operating these systems less than the cost of a single generalized system? I believe that the answer will often be in favor of a single system even when the specialized systems are low-cost open source. Since “fit” is about cost maybe one size does fit now and again.
This suggests the strategy of the OldSQL vendors. They are offering a Swiss Army Knife product that serves multiple requirements. Their feature sets have grown over 30 years and they are pretty capable across a wide array of business problems… and with the columnar and in-memory features being added they continue to cover ever more extreme uses cases… not the most extreme use cases… but they cover more ground each year.
The strategy of the NewSQL vendors is to focus tight and hard. They might develop an extreme OLTP DBMS with no ability to do a join… a product with extreme scalability and no performance… or a graph database to solve for an important, narrow, set of queries… or a columnar product that performs analytics but support no OLTP. This trend feeds the specialize and replicate meme advocated by Dr. Stonebreaker.
HANA is a horse of a different color… neither NewSQL nor OldSQL. It is a new code base designed to solve for a very wide set of uses cases in a single instance of the data. We certainly agree in this blog with Dr. Stonebreaker’s contention that the 30 year old legacy code base has to be retired. But SAP contends that you can build a new, generalized, DBMS that solves for all but the most extreme cases.
This is a great spot to end the year… having laid out the battle we will cover in this blog ongoing… with the legacy OldSQL vendors trying to tack on to their legacy code base… and doing pretty well at it… with the NewSQL vendors trying to specialize and replicate… and with HANA offering a new code base designed to solve for the the whole picture. 2014 will be great fun to watch. This also sets the stage to ask next year whether “big data” applications are so extreme as to force users to specialize-replicate-specialize.
Have a great holiday season… and my best wishes. Thank you all for reading the Database Fog Blog in 2013… I hope for your continued attention in the New Year…
Forrester regularly provides fodder for bloggers when they report on the EDW space (see Curt Monash’s review of their last report here). They have a 2013 report out now that is quite mysterious (see here).
They report that Pivotal is up there with the leading EDW vendors and positioned to move further up.
Here is the mystery. If you go to the Pivotal site and search on “data warehouse” you get ten hits:
Eight talk about analytic data warehouses, not enterprise data warehouses;
One talks about using Hive as a data warehouse; and
One talks about data and sandboxing.
There are no hits on the term “enterprise data warehouse” and one hit on the term “EDW” which refers to why you should move data off of the EDW to an analytic platform.
As I’ve pointed out… Pivotal does not market into the EDW space. They are not developing product for that space. EDW is not part of their product strategy.
The fact that their product is a capable platform for an EDW is worth noting… and readers of this blog should consider GPDB, aka Greenplum, for EDW projects. But you should be fully aware of the risk that Pivotal is not really backing this use case.
For an analyst to suggest that Pivotal has an industry-leading strategy in a space that they are not pursuing at all is very odd.
I have suggested that the big EDW parallel databases: Teradata, Exadata, Greenplum, and Netezza in particular will be squeezed over time. Colder data will move from those products to Hadoop and hotter data will move in-memory. You can see posts on this here, here, and here.
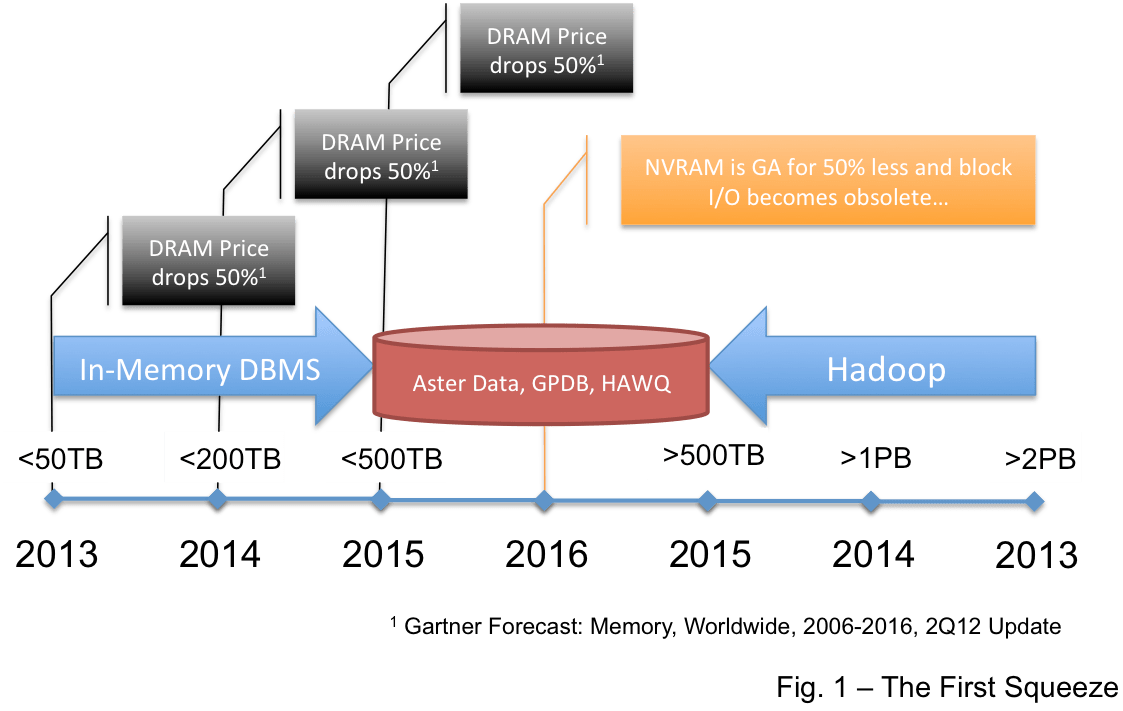
But there are three products, the Greenplum database (GPDB), HAWQ, and Aster Data, that will be squeezed more quickly as they are positioned either in between the EDW and Hadoop… or directly over Hadoop. In this post I’ll explain what I suspect Pivotal and Teradata are trying to do… why I believe their strategy will not work for long… and why readers of this blog should be careful moving forward.
The Squeeze picture assumes that Hadoop consumes more and more “big data” over time as the giant investment in that open source eco-system matures the software and improves both the performance and the feature base. I think that this is a very safe assumption. But the flip side of this assumption is that we recognize that currently the Hadoop eco-system is not particularly mature and that the performance is not top-notch. It is this flip side that provides the opportunity targeted by Pivotal and Teradata.
Here is the situation… Hadoop, even in its newbie state, is lowering the price point for biggish data. Large EDW implementations, let’s say over 100TB, that had no choice but to pick a large EDW database product 4 years ago are considering and selecting Hadoop more often at a price point 10X-20X less than the lowest street price offered by commercial DBMS vendors. But these choices are painful due to the relatively immature state of the Hadoop eco-system. It is this spot that is being targeted by Aster and GPDB… the “big data” spot where Aster and GPDB can charge a price greater than the cost of Hadoop but less than the cost of the EDW DBMS products… while providing performance and maturity worth the modest premium.
This spot, under the EDW and above Hadoop is a legitimate niche where revenue can be generated. But it is the niche that will be the first to be consumed by Hadoop as the various Hadoop RDBMS features mature. It is a niche that will not be commercially interesting in two years and will be gone in four years. Above is the Squeeze picture updated to position Aster, HAWQ and GPDB.
What would I do? Pivotal has some options. First, as I have stated before, GPDB is a solid EDW DBMS and the majority of it’s market even after running from the EDW space is there. They could move up the food chain back to the EDW space where they started and have an impact. This impact could be greater still if they could find a way to build a truly effective cloud-based EDW DBMS out of the GPDB. But this is not their current strategy and they are losing steam as an EDW both technically and in the market. The window to move back up is closing. Their current strategy which is “all-in” on Hadoop will steal business from GPDB for low-margin business around HAWQ and steal business from HAWQ for an even lower-margin business around Pivotal Hadoop. I wonder how long Pivotal can fund this strategy at a loss?
I’m not sure what I would do if I were Teradata? The investment in Aster Data is not likely to pay off before Hadoop consumes the space. Insofar as it is a sunk cost now… and they can leverage the niche described above… their positioning can earn them some revenue and stave off the full effect of the Squeeze for a short time. But Aster was never really a successful EDW play and there is no room for it to move up the food chain at Teradata.
What does this mean? Readers should take note and consider the risk that Hadoop wins in the near term… They might avoid a costly move to Aster or GPDB or HAWQ with a short lifespan. Maybe it is time to bite the bullet now and start introducing Hadoop into your infrastructure?
One final note… it is not my expectation that either the Hadoop DBMS nor any NoSQL DBMS product will consume the commercial RDBMS space anytime soon. There are reasons for this… stay tuned and I’ll post on this topic in the new year.
With this post the Database Fog Blog will receive its 100000th view. I am so grateful for your attention and consideration. And with this last post of my calendar year I wanted to say thanks… to send my regards to all whether you will be celebrating a holiday season or not… and to wish every reader, regardless of what calendar you follow, all the best in the next year…
The Chinese Curse wishes that you live in interesting times… although apparently it is not so certain that this is either a curse or Chinese. During this Northern Hemisphere harvest season I would like to wish my readers a Happy Thanksgiving… and note how thankful I am to live and work in interesting times and in such an interesting slice of the technology market… and doubly thankful for my readers and their interest.

(15884 bytes) - a typical...")